데이터 수집
데이터 수집
문제 정의와 설정
- 목표 설정이 중요한 이유
- 데이터 수집 전에 목표를 정확히 정의하면 필요한 데이터의 형태와 특성을 파악할 수 있음
- 불필요한 데이터 수집을 방지
- 고품질의 데이터 확보 가능
- 목표를 잘못 설정할 경우
- 데이터의 품질 저하로 AI 모델의 성능이 떨어짐
- 시간과 자원의 낭비
목적에 맞는 데이터 요구사항 분석
- 모델에 필요한 유형 : 텍스트, 이미지, 음성 등
- 감정 분석 모델에는 레이블링된 테스트 데이터 필요

- 이미지 분류 모델은 이미지 정보와 정확한 카테고리 레이블 필요

다양하고 풍부한 데이터 확보
- 데이터의 다양성
- 다양한 특성(연령, 성별, 지역 등)을 가진 데이터는 모델의 일반화 성능을 향상
예시 구체적인 데이터 예시 기대 효과 음성 인식 모델 - 여러 국가의 억양
- 시끄러운 거리 소음에서의 음성- 다양한 사용자 환경에서도 높은 인식률
- 억양과 배경 소음의 다양성이 높을수록 더 정확한 인식이 가능챗봇 모델 - 여러 언어의 대화
- 구어체와 문어체 혼합된 텍스트- 다국어 지원 및 문맥에 따른 정확한 답변
- 다양한 언어와 표현 방식에 대응 가능하여 다국적 사용자와 원활히 소통 가능 - 데이터의 풍부성
- 모델 학습에 사용되는 데이터의 양을 의미
- 충분한 양의 데이터는 모델이 더 많은 패턴과 관계를 학습할 수 있도록 도움
- 데이터 양이 적으면 과적합(overfitting) 될 가능성이 높아짐
- 충분한 데이터는 모델의 신뢰성을 높임
- 데이터의 정확성
- 데이터의 정확성은 수집된 데이터가 얼마나 정확하고 신뢰할 수 있는지를 나타냄
- 모델이 정확한 정보를 기반으로 학습해야 함
- 잘못된 데이터는 모델 학습을 왜곡
- 노이즈(noise)가 섞인 데이터는 모델의 신뢰성을 저하
데이터 수집의 범위와 한계 설정
- 범위 설정의 중요성
- 불필요한 데이터 수집을 줄여 효율성을 높임
- 데이터 범위를 설정하여 정확한 목표에 맞춘 수집 가능
- 한계 설정
- 법적, 윤리적 제한 사항을 고려하여 수집
- 예시 : 개인정보를 포함한 데이터 수집 시 법적 절차 준수 필요
- 법적, 윤리적 제한 사항을 고려하여 수집
목적에 따른 목표 데이터 예시
고객 리뷰의 감정(긍정, 부정, 중립) 분류
예시 목표를 명확히 정의한 경우 목표를 명확히 정의하지 않은 경우 감정 분석 AI 모델 - 필요한 데이터: 제품 리뷰, SNS 포스트 등의 레이블링된 텍스트 데이터
- 수집된 데이터는 감정(긍정, 부정, 중립)이 명확하게 레이블링되어 있어야 함
- 특정 언어, 문체, 그리고 특정 제품 카테고리에 대한 데이터로 집중하여 모델의 예측 정확도를 높임- 관련 없는 주제의 리뷰나 SNS 데이터를 무작위로 수집하여 정확도 저하
- 복합적인 언어 및 중복된 데이터를 포함해 처리 비용과 시간 증가
- 감정 분석에 필요하지 않은 비정형 데이터가 포함되어 모델 성능이 저하됨특정 질병을 조기에 진단하기 위한 AI 모델 개발
예시 목표를 명확히 정의한 경우 목표를 명확히 정의하지 않은 경우 의료 진단 AI 모델 - 필요한 데이터: 환자의 CT 스캔 이미지 및 해당 진단 결과 레이블
- 데이터의 해상도와 포맷을 사전에 설정하여, 일관성 있는 이미지를 수집
- 특정 연령대, 성별, 지역을 고려해 대표성 있는 데이터 확보- 다양한 질병의 의료 이미지를 무작위로 수집하여 분석 혼선 발생
- 관련 없는 진단 정보를 포함해 모델 훈련 시 오류 발생 가능성 증가
- 환자 개인정보를 보호하지 않고 수집하여 법적 문제 초래자율주행 차량이 도로 상황 인식 및 장애물 회피
예시 목표를 명확히 정의한 경우 목표를 명확히 정의하지 않은 경우 자율주행 도로 인식 모델 - 필요한 데이터: 다양한 날씨, 시간대, 도로 조건에서 촬영된 도로 이미지와 비디오
- 도로 표지판, 차선, 보행자 등 특정 객체에 대한 레이블링이 포함된 데이터 확보
- 도심, 고속도로, 주거 지역 등 다양한 환경 데이터를 포함하여 모델의 일반화 성능 향상- 단일 날씨 조건(맑은 날)이나 특정 지역에서만 데이터를 수집해 모델이 다양한 상황에서 작동하지 않음
- 보행자나 도로 표지판 등의 레이블이 누락된 데이터로 훈련 시 안전 문제 발생 가능
- 불필요한 객체가 포함된 데이터를 사용해 모델의 혼란 가중고객 문의 자동 응답
예시 목표를 명확히 정의한 경우 목표를 명확히 정의하지 않은 경우 챗봇 AI 모델 - 필요한 데이터: FAQ (Frequently Asked Questions), 고객 문의 데이터와 이에 대한 답변 사례
- 특정 산업 및 국가(예: 한국의 은행 챗봇은 금융과 한국어에 집중된 데이터)에 맞춘 특화된 데이터 수집
- 문맥과 질문 의도에 따라 정확한 레이블링을 통해 챗봇의 응답 정확도 향상- 범용 대화 데이터만 수집하여 특정 도메인에서의 응답 부정확
- 여러 언어의 데이터를 섞어 수집해 챗봇의 언어 처리 혼란 초래
- 중복된 데이터나 불필요한 대화 내용으로 인해 모델 학습 시간 증가
법적 / 윤리적 고려 사항
개인정보 보호 및 프라이버시 문제
- 개인정보 보호
- AI 모델 개발 시 개인의 데이터를 수집할 때 프라이버시 침해 발생 가능
- 데이터를 안전하게 관리하지 않으면 신뢰도 저하와 법적 처벌로 이어질 수 있음
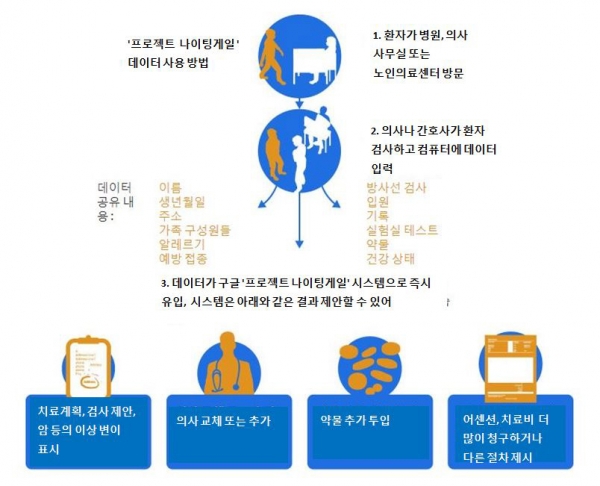
- 예시 : 구글의 ‘프로젝트명 : 나이팅게일’
- 의료 데이터, 위치 정보, 대화 기록 등 민감 정보의 무단 수집 및 유출
- 부정확한 개인정보 처리로 인한 개인 피해 및 법적 분쟁 발생
윤리적 데이터 수집과 책임
- 최소 데이터 수집 원칙
- 필요한 데이터만 수집하여 프라이버시 침해 최소화
- 예시 : 성별에 대한 분류 데이터를 수집할 때, 주소나 위치 등의 개인정보를 제외한 성별만을 수집
- 목적 제한 원칙
- 수집한 데이터는 사전에 정의된 목적에만 사용
- 예시 : 마케팅 목적의 데이터가 의료 연구에 사용되지 않도록 제한
법적 고려사항을 반영한 데이터 수집 계획
PIA(Privacy Impact Assessment, 개인정보 영향 평가)
개인정보가 사용되는 프로젝트에서 개인정보에 미칠 수 있는 잠재적 영향을 평가하고 이를 완화할 수 있는 대책을 마련하는 절차
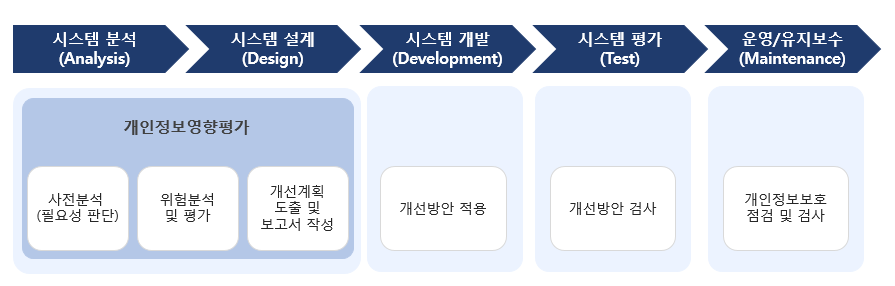
예시 : 학생 출석 자동화를 위한 얼굴 인식 시스템 도입 과정
단계 1) 데이터 수집 목적 2) 데이터 흐름 분석 3) 프라이버시 위험 분석 4) 보호 대책 수립 5) 결과 보고 및 문서화 설명 출석 체크의 효율성을 높이기 위해 학생 얼굴 데이터를 수집 학생, 교사만 접근 가능하도록 데이터 접근을 제한하고 외부 접근 차단 얼굴 인식 데이터가 유출될 경우 학생 프라이버시 침해 가능성 얼굴 인식 데이터 암호화, 접근 권한 제한, 시스템 접근 기록 모니터링 학부모 동의를 받은 후 PIA 보고서를 작성하고 학교 이사회에 제출
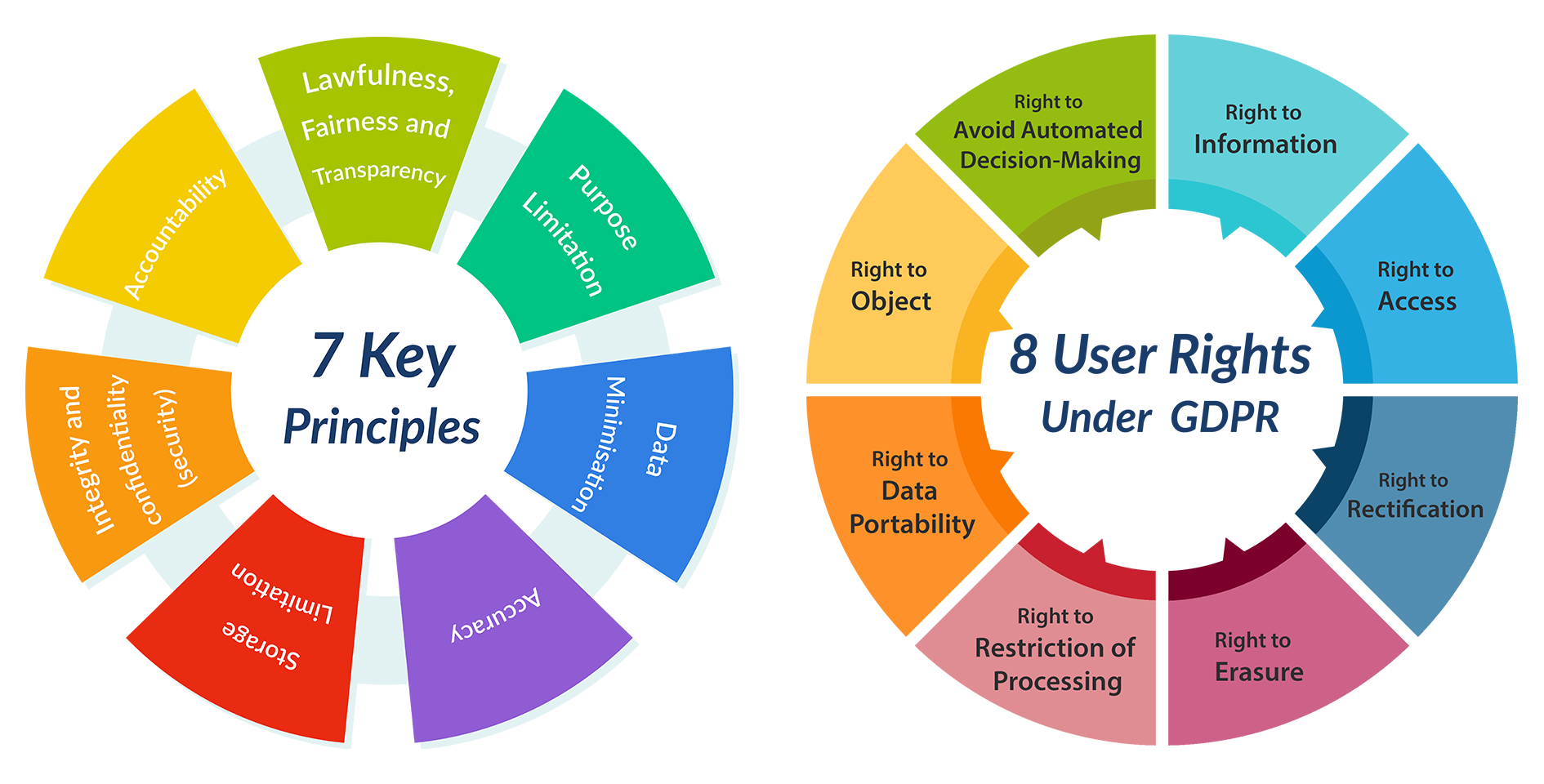
GDPR(General Data Protection Regulation, 유럽연합 일반 개인정보 보호법)
- 실효성 있는 정보보호를 위해 유럽이 도입한 제도
- 개인의 개인정보를 보호하고, 데이터 처리와 관련된 투명성과 신뢰성을 강화하기 위해 제안
- GDPR에는 원칙과 사용자 권리가 존재
GDPR 위반 시 최대 매출의 4% 또는 2천만 유로 중 더 높은 금액을 벌금으로 부과
- 예시 : 모바일 앱에서 위치 정보 수집
- 사용자가 명확한 동의를 한 경우에만 위치 데이터 수집
- 데이터 수집 시 사용자에게 목적과 저장 기간을 명확히 설명
- 언제든지 위치 데이터 수집을 거부하거나 삭제할 수 있는 옵션 제공
마스킹(masking)
- 데이터를 보호하기 위해 특정 부분을 숨기는 기술
- 원본 데이터는 유지하되, 특정 민감한 정보를 부분적으로 가려서 접근을 제한
- 일부만 숨기므로 분석이나 운영에 필요한 데이터 활용이 가능
- 예시
- 신용카드 번호 마스킹 :
1234-5678-1234-5678→****-****-****-5678로 표시
- 신용카드 번호 마스킹 :
익명화(anonymization)
- 데이터에서 개인을 식별할 수 있는 모든 정보를 완전히 제거하거나 변환하여, 특정 개인과 연결되지 않도록 만드는 기술
- 익명화된 데이터는 개인을 식별할 수 있는 정보가 없기 때문에, GDPR과 같은 개인정보 보호 규정의 적용을 받지 않음
- 익명화된 데이터는 연구, 분석, 통계 목적으로 안전하게 활용 가능
- 예시
- 의료 데이터 익명화 : 연구 목적을 위해 환자의 이름, 생년월일, 주민번호 등 식별 정보 제거
데이터의 편향
편향이란?
- 사전적 정의 : 한 쪽으로 치우침
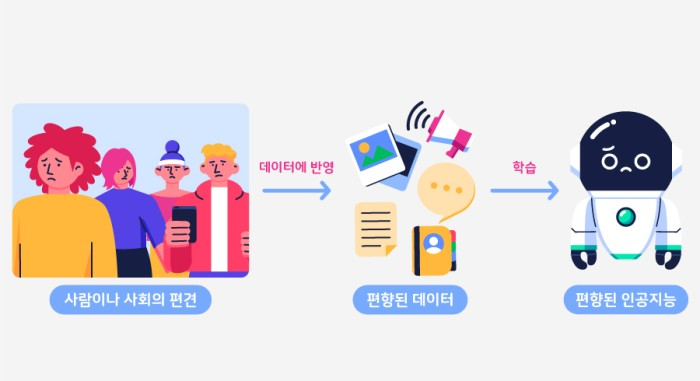
- 인공지능의 편향
- 편향된 데이터로 인해 편향된 결과를 출력
- 수많은 데이터를 학습함에 따라 사회에 내재된 편견을 흡수
모델 알고리즘 자체의 문제가 있는 경우도 있음
- 예시
- 아마존 채용 프로그램
LLM 모델 별 정치적 성향

편향의 발생 원인
- AI 시스템의 80%는 데이터로 구성
- AI의 편향은 학습되는 데이터로부터 발생할 가능성이 큼
- Code
- 알고리즘 문제
- Data
- 데이터 수집 및 라벨링 문제
- 전처리 문제
- Code
편향의 종류
표본 편향(Sample Bias)
- 선택 평향(Selection Bias) 라고도 불림
- 데이터가 전체 모집단을 적절히 대표하지 못하는 경우 발생
- 데이터 수집 과정에서 특정 그룹을 과대 또는 과소 대표
- 표본의 크기가 충분히 크지 않거나 무작위성을 확보하지 못함
- 예시
2차 대전 당시 미군 전투기의 탄흔 숫자 분석

측정 편향(Measurement Bias)
- 데이터를 측정하거나 기록하는 과정에서 오류 혹은 불일치 발생
- 데이터 측정 도구의 부정확성
- 데이터를 라벨링하는 과정에서 발생하는 실수
- 예시
- 스마트폰 센서로 걸음 수를 측정할 때 기기 문제로 과소 측정
- 법적 판결 데이터 학습 시 판사의 편견이 반영된 레이블
라벨링이 잘못된 강아지 데이터

사회적 편향(Social Bias)
- 데이터에 사회적 고정관념, 차별, 불편등이 반영
- 이미 사회에 많이 녹아들어 있는 편향
- 데이터 수집 과정에서 특정 집단의 특성이 과잉 반영
- 예시
- 번역 모델이 Doctor를 남성으로 지칭하고 Nurse를 여성으로 지칭
- 특정 인종에 대한 의료 정확도가 낮음
확증 편향(Confirmation Bias)
- 기존 가설을 강화하거나 뒷받침하는 데이터만 선택적으로 사용
- 연구자나 데이터 과학자가 원하는 결과를 지지하는 데이터만 사용
- 반대되는 데이터를 무시하거나 배제
- 예시
- 특정 약물이 효과적이라는 실험 결과만 선택
- 긍정적인 리뷰만 수집
데이터 불균형(Imbalance Bias)
- 특정 클래스가 다른 클래스에 비해 과대 또는 과소 대표하여 균형이 맞지 않음
- 데이터의 자연적 분포가 불균형
- 수집 과정에서 특정 클래스가 배제됨
- 예시
- 희귀한 질병 데이터가 적어 모델이 해당 질병을 제대로 탐지하지 못함
알고리즘 편향(Algorithmic Bias)
- 데이터 편향 뿐만 아니라, 알고리즘의 설계, 모델 학습 과정에서 발생하는 편향
- 알고리즘이 최적화하려는 목적 함수가 공정성을 고려하지 않고 설계된 경우
- 출력 결과가 다시 데이터로 피드백이 되며 편향이 강화
- 예시
- 고객 대출 승인 모델이 대출 승인률 최대화를 목표로 설계된 경우, 소득이 낮은 그룹은 과소평가됨
- 추천 시스템이 인기 콘텐츠만 반복적으로 추천하여 다양성 감소
편향이 모델에 미치는 영향
- 일반화 능력 부족
- 특정 그룹에 대해 과적합 된 결과를 냄
- 실제 배포 환경 및 새로운 데이터에 대해서는 낮은 성능
- 공정성 문제
- 모델이 특정 그룹에 유리하거나 불리한 결과를 초래하여 윤리적 문제를 발생
Bias와 Variance
- Bias(편향)
- 모델이 학습 데이터로부터 얻은 추정값이 실제 정답(목표값)과 얼마나 다른지를 나타냄
- 모델이 학습 데이터의 패턴을 제대로 학습하지 못해 발생하는 오류
- 편향이 높은 모델은 데이터 내에 패턴을 통해 제대로 예측하지 못하기에 보통 일관되게 정답을 벗어남
- Variance(분산)
- 모델이 학습 데이터의 작은 변동에 얼마나 민감하게 반응하는지를 나타냄
- 학습 데이터의 세부적인 패턴을 과도하게 학습하여 새로운 데이터에서 일반화가 어렵게 되는 경우 발생
- Bias-Variance Trade off
- 머신러닝에서 과소적합(Underfitting)과 과적합(Overfitting) 사이의 균형을 설명하는 개념
Bias와 Variance를 적절히 조정하여 최적의 일반화 성능을 얻는 것

- Bias와 Variance가 균형을 이루는 지점을 찾아야 함
- 간단한 모델은 패턴을 제대로 학습하지 못해서 Bias가 높고, 예측치의 가변성이 작으므로 Variance가 낮음
복잡한 모델은 패턴을 잘 해석하기에 Bias는 낮아 내재된 패턴을 더 잘 포착할 수 있으며, 훈련 데이터에 “너무” 잘 맞기에 예측치의 가변성이 높아서 Variance가 높음
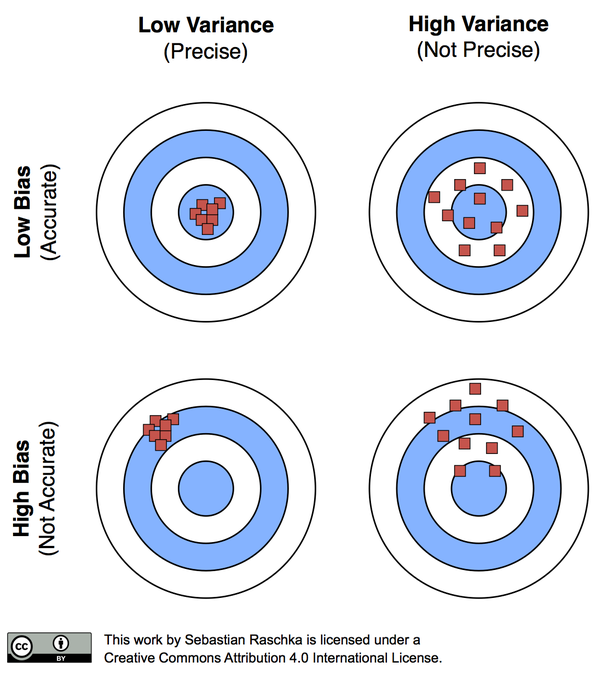
편향 완화 전략
데이터 수집
- 데이터 수집의 목적을 명확히 함
- 대표성 있는 데이터 수집
- AI 모델이 학습 데이터에서 다양한 특성과 집단을 공정하게 학습할수 있도록 설계
- 일반화 능력 향상 : 모델이 모집단 전반에 대해 잘 설명할 수 있음
- 공정성 확보 : 특정 집단에 치우치는 불공정한 결과 방지

- 데이터 수집 범위 확장
- 데이터 수집 과정에서 발생할 수 있는 불일치와 편차를 최소화
- 무작위 샘플링
- 모집단의 다양한 특성을 공정하게 반영하는 데이터 확보
- 충화 샘플링
- 모집단의 중요한 특성으로 나누고 각 그룹에서 균등하게 데이터를 수집
- 데이터 증강
- 현실적으로 수집이 어려운 데이터는 증강 기법으로 보완
- 데이터 수집 기준 표준화 - 데이터 수집 과정에서 발생할 수 있는 불일치와 편차 최소화 - 데이터 품질 향상 : 일관된 기준으로 수집된 데이터로 정확성 향상 - 재현성 확보 : 동일 조건에서 수집한 데이터는 이후 실험과 분석의 재현성이 높아짐
- 현실적으로 수집이 어려운 데이터는 증강 기법으로 보완
- 수집 도구 표준화
- 카메라, 센서 등의 수집 장비의 사양을 동일하게 유지
- 수집 프로세스 표준화
- 수집 절차를 문서화하여 모든 수집자가 동일한 방법을 따르도록 함
- 데이터 포맷 표준화
- 데이터의 형식과 구조를 통일하여 데이터 처리의 일관성 확보
데이터 전처리
- 수집한 데이터의 균형이 맞지 않을 경우 전처리를 통해 이를 해결
- 데이터 균형화
- 데이터셋 내 클래스 간 불균형을 완화하여 편향되지 않도록 조정
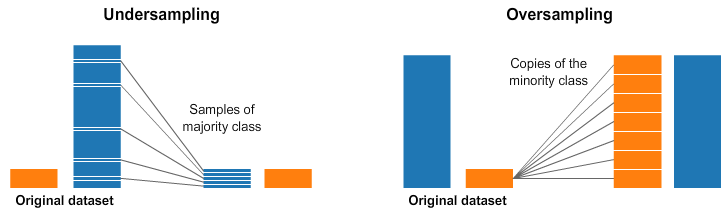
- 오버샘플링
- 소수 클래스의 데이터를 늘림
- 노이즈가 증폭될 가능성 존재
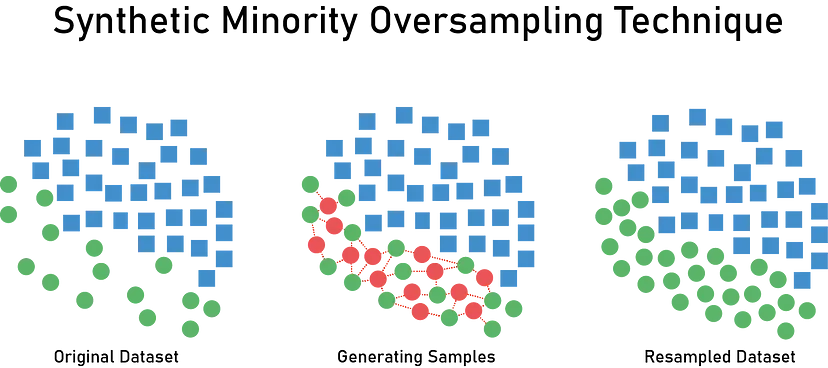
- SMOTE(Synthetic Minority Oversampling Technique)
- 소수 클래스의 데이터를 기반으로 새로운 데이터를 합성
- 이웃 데이터 포인트 사이에 임의의 값을 생성
- ADASYN(Adaptive Synthetic Sampling Approach)
- 소수 클래스 데이터를 확대하되, 데이터 분포의 복잡성을 고려하여 생성
- 학습하기 어려움 샘플(소수 클래스 데이터 주변에 다수 클래스 데이터가 많은 경)에 더 많은 데이터 생성

특징 SMOTE ADASYN 샘플링 방식 균일하게 샘플을 생성 모델 학습에 어려운 영역에 더 많은 샘플 생성 데이터 밀도 데이터 분포의 불균형을 고려하지 않음 소수 클래스 데이터 분포의 불균형 반영 적용 영역 단순한 데이터 불균형 문제 해결에 적합 복잡한 경계 문제를 해결할 때 적합 - 언더샘플링
- 다수 클래스의 데이터를 줄임
- 정보가 손실될 가능성 존재
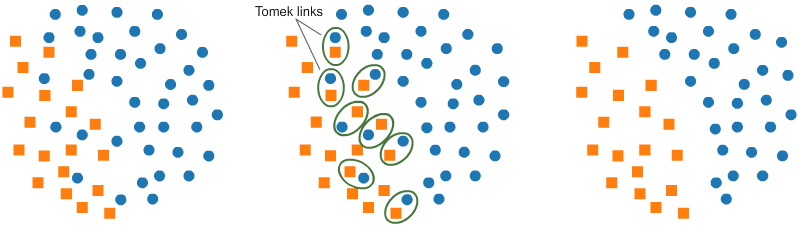
- Tomek Links
- 가장 가까운 두 데이터를 묶었을 때 각 데이터가 서로 다른 클래스에 속하는 것을 의미
- 이들을 찾아 제거하여 데이터의 경계를 명확히 하고 모델이 경계에서 더 정확히 학습할 수 있도록 도움
- CNN(Condensed Nearest Neighbor)
- 과정
- 다수 클래스에서 데이터 하나를 뽑고, 소수 클래스 전체를 합집합한 것을 S 집합으로 둠
- 다수 클래스 데이터 중 하나를 뽑아 소수 클래스와 더 가까우면 해당 데이터를 S에 포함시킴
- 더 이상 선택되는 데이터가 없을 때까지 이를 반복(1-NN으로 분류되지 않는 데이터만 남기는 것)
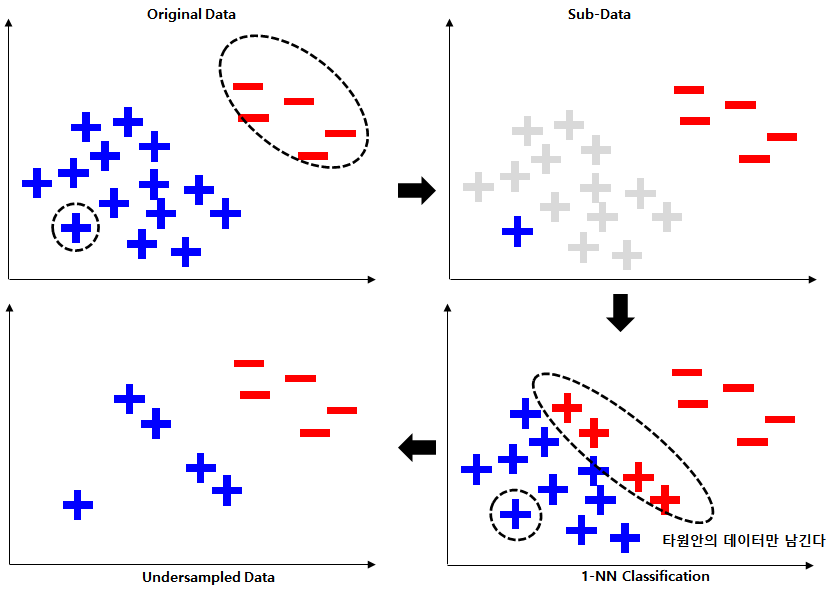
- 과정
- 복합샘플링
- SMOTE-Tomek
- SMOTE로 오버샘플링 수행하여 데이터를 증강
- 증강된 데이터에서 경계에 위치한 Tomek-Link를 찾아 제거
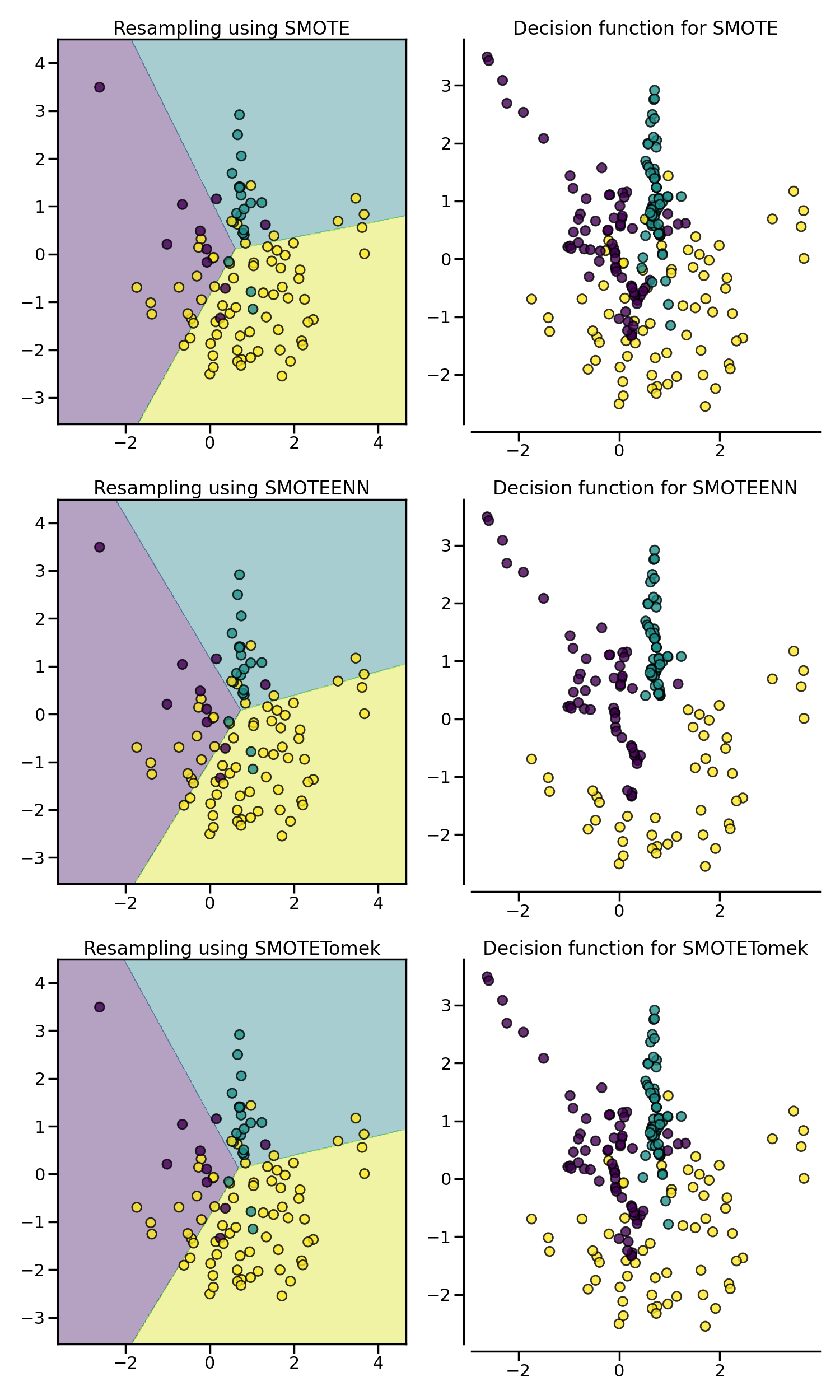
- OSS(One Sided Selection)
- Tomek Links로 데이터셋의 경계를 확실히 만듦
- 이후 CNN을 적용하여 경계와 멀리 떨어진 데이터를 제거

- SMOTE-Tomek
모델
- 모델 알고리즘을 수정하여 편향 출력을 방지할 수 있음
- 모델 완성 후 모니터링을 통해 편향 감지
- 모델 학습 단계
- 공정성 제약(Fairness Constraints) - AI 모델 학습 과정에서 공정성을 목표로 하는 제약 조건을 추가하여 편향되지 않도록 조정 - 편향된 데이터가 입력되더라도 어느 정도 보정 가능 - 과정
- 목적 함수에 공정성 제약 추가
- $\text{min} \, \text{Loss}(Y, \hat{Y}) + \mu \times \text{Fairness Constraint}$
- $\mu$ : 공정성과 성능 간의 균형을 조정하는 가중치
- 민감 특성(예: 성별, 인종)과 예측 간 상관관계 최소화
- $\text{min} \, \text{Loss}(Y, \hat{Y}) + \mu \times \text{Correlation}(\hat{Y}, A)$
- 예측 결과$(\hat{Y})$를 예측하는 민감 특성$(A)$의 상관관계를 줄임
- 공정성과 성능 간의 균형을 조정하는 가중치
- 목적 함수에 공정성 제약 추가
- Adversarial Debiasing - 적대적 학습(Adversarial Training)을 활용하여 AI 모델의 편향 완화 - 절차
- *생성자(예측 모델)**는 민감 특성을 포함하지 않고 목표를 예측하도록 학습
- $L_{\text{predict}} = \text{Loss}(Y, \hat{Y})$
- 생성자의 목표 변수 $Y$를 예측하는 정확도
- 판별자는 생성자의 예측 결과에서 민감 특성을 복원하려고 시도
- $L_{\text{adversary}} = \text{Loss}(A, \hat{A})$
- 판별자의 민감 특성 $A$를 예측하는 정확도
- 생성자는 판별자가 민감 특성을 예측하지 못하도록 학습
- $L_{\text{total}} = L_{\text{predict}} - \mu \, L_{\text{adversary}}$
- 생성자는 두 손실을 동시에 최적화하도록 설정
- *생성자(예측 모델)**는 민감 특성을 포함하지 않고 목표를 예측하도록 학습
- 모델 평가 단계
- 모델 완성 및 배포 이후에도 지속적으로 관리가 필요
- 공정성 평가 지표 사용
- 구축한 모델이 공정하게 작동하는지 평가
- 교차 검증으로 모델이 다양한 시나리오에서 일관되게 작동하는지 평가 2. 모니터링
- 데이터 분포를 분석하며 새로운 편향이 발생하는지 감지
- 시간이 지남에 따라 데이터 분포의 변화를 반영
- 모델 완성 및 배포 이후에도 지속적으로 관리가 필요
데이터 수집 방법
크롤링
- 자동화된 스크립트(봇)을 이용해 웹 페이지를 자동으로 탐색하고 데이터를 수집하고 저장하는 과정
- 주로 검색 엔진에서 웹 페이지를 수집하여 색인(indexing)하거나, 데이터 분석 및 연구를 위해 대량의 데이터를 수집
- 원리
- 크롤러가 특정 웹 페이지에 접근하여 HTML 코드를 다운로드한 후, 필요한 정보를 자동 추출
- 크롤러는 웹 페이지의 링크를 따라가며 연속적으로 페이지를 탐색하여 데이터를 수집
- 수집한 데이터를 정제 및 가공하여 분석 가능한 형태로 저장
수집 단계 설명 HTTP 요청 크롤러가 웹 페이지에 접근하기 위해 HTTP 요청 보냄 HTML 응답 서버로부터 HTML 코드를 포함한 응답 수신 HTML 파싱 BeautifulSoup과 같은 라이브러리를 사용하여 HTML 구조 분석 및 데이터 추출 데이터 저장 및 분석 추출한 데이터를 CSV, JSON, XML 등으로 저장하여 분석에 활용 관련 용어
용어 정의 및 설명 웹 스크래핑 (Web Scraping) 크롤링과 유사하지만, 주로 특정한 정보 (예: 가격 정보, 리뷰 등)를 추출하여 가공하는 데 중점을 둠 데이터 랭글링 (Data Wrangling) 수집된 원자료(Raw Data)를 변환 및 매핑하는 과정 파싱 (Parsing) HTML, XML 등의 문법적 구조를 해석하여 필요한 데이터를 추출 인덱싱 (Indexing) 검색 속도를 높이기 위해 데이터베이스에 색인을 생성하는 작업 슬라이싱 (Slicing) 리스트와 같은 순회 가능한 객체의 특정 부분을 잘라내는 작업 - 과정
- Robot.txt 기준을 확인하여 크롤링 가능한 웹사이트인지 확인
- Urllib나 Request 라이브러리로 해당 사이트를 불러와서 BeautifulSoup로 HTML 문서를 파싱
- HTML의 구조를 파악하여 find문이나 select문을 이용하여 추출하고자 하는 부분을 찾아 텍스트 문서로 추출
- 정규표현식(re)나 KoNLPy 라이브러리를 이용해 텍스트를 정제하여 필요한 정보를 접근
- 고려 사항
- 윤리적 문제
- 대량의 요청을 보내면 웹 서버에 과부하를 유발할 수 있어 서비스 장애 유발
- 크롤링 시 적절한 요청 간격을 두어 서버에 무리를 주지 않도록 해야 함
- 사용자의 동의 없이 이메일, 전화번호 등 개인 정보를 수집할 수 있음
- GDPR과 같은 개인정보 보호법을 위반할 경우 법적 처벌 가능
- 대량의 요청을 보내면 웹 서버에 과부하를 유발할 수 있어 서비스 장애 유발
- 법적 문제
- 일부 웹사이트는 이용 약관에 따라 크롤링을 금지하며, 이를 무시하고 데이터를 수집하면 법적 분쟁 발생 가능
- 유로 콘텐츠나 구독 기반 사이트
- 웹 페이지의 콘텐츠를 무단으로 수집하여 상업적 목적으로 사용하는 경우 저작권법 위반에 해당
- 예시
- 뉴스 사이트의 기사를 크롤링하여 자신의 블로그에 게시하면 저작권 침해로 고소 가능
- 야놀자 vs 여기여때 법적 분쟁
- 일부 웹사이트는 이용 약관에 따라 크롤링을 금지하며, 이를 무시하고 데이터를 수집하면 법적 분쟁 발생 가능
- 윤리적 문제
Robots.txt
- 웹사이트에서 크롤러의 접근을 제어하기 위해 사용하는 텍스트 파일
- 웹사이트 소유자가 크롤러가 접근 가능한 영역과 제한해야 할 영역을 정의
- 권고 사항이며, 강제성은 없음
| 용어 | 설명 |
|---|---|
| User-agent | 특정 크롤러를 지정하거나, *을 사용하여 모든 크롤러에 적용 |
| Disallow | 크롤링을 차단할 경로 설정 |
| Allow | 특정 경로는 크롤링을 허용 |
| Sitemap | 크롤러에게 사이트맵 위치를 알려줌으로써 더 효율적으로 크롤링을 수행하도록 안내 |
크롤링 라이브러리
- Requestes
- 정적 수집도구
- 단순한 형태의 문법, 인코딩 확인, 헤더 파악, 텍스트 전환이 용이하고, 딕셔너리 형태로 데이터 전송
- 외부 라이브러리
- 자동 디코딩(덱스트 데이터)
- Urllib
- 정적 수집도구
- 데이터를 바이너리 형태로 인코딩하여 데이터 전송(디코딩 필요)
- Python 표준 라이브러리(설치 불필요)
- Urlopen()을 포함한 다소 복잡한 접근 방법
- Selenium
- 동적 수집도구
- 웹 브라우저 드라이버 설치 필요
- 웹 애플리케이션의 테스트를 자동화할 수 있도록 설계된 오픈 소스 프레임워크
- 다양한 브라우저를 지원하며, 여러 프로그래밍 언어(Python, Java, C#, Ruby 등)로 제어
- 동적인 여러가지 상호작용(버튼 클릭 등)으로 데이터 수집
- 웹사이트가 자바스크립트로 동적 컨텐츠를 로드하는 경우, Selenium을 통해 브라우저를 집적 제어하여 동적 페이지의 콘텐츠도 스크래핑 가능
- BeautifulSoup
- 본문 파싱을 위한 도구
- HTML 문법으로 작성된 문서를 파싱하여 필요한 부분의 태그를 기준으로 데이터 추출 및 정제
- HTML 문서를 단순한 파이썬 객체처럼 다룰 수 있어 직관적이고 사용이 간편
- 파이선 내장 파서(html.parser), lxml, html5lib 등 다양한 HTML 파서 지원하여 성능과 호환성 선택 가능
- CSS 선택자, 태그, 속성 등 다양한 방식으로 데이터를 선택할 수 있어 복잡한 웹 페이지에서도 유용

데이터 포맷
CSV
- 데이터를 쉼표로 구분하여 저장한 텍스트 파일 형식
- 각 줄은 레코드(record), 쉼표로 구분된 값들은 필드 (field)
- 프로그래밍 언어에서 쉽게 읽고 쓰기 가능
- 저장 공간을 적게 사용하고 처리 속도가 빠름
JSON
- JavaScript에서 파생된 경량 데이터 교환 형식
- 사람이 읽기 쉽고 기계가 분석 및 생성하기 쉬운 구조
- Key-Value 쌍으로 이루어진 데이터 구조
XML(eXtensible Markup Language)
- 데이터의 구조와 의미를 설명하기 위해 태그를 사용하는 언어
- 사용자 정의 태그를 사용하여 데이터를 표현
- 계층적 구조와 속성(attribute)를 사용하여 다양한 데이터 형태를 표현 가능
| 데이터 포맷 | CSV | JSON | XML |
|---|---|---|---|
| 장점 | - 단순한 구조로 처리 속도가 빠름 - 다양한 도구에서 지원 - 파일 크기가 작아 전송 효율성 높음 | - 데이터 용량이 작고 속도가 빠름 - 가독성이 높음 - 웹 개발에 최적화 | - 복잡한 구조 지원 - 사용자 정의 태그 사용 - 다양한 플랫폼과 언어에서 사용 |
| 단점 | - 계층적 데이터 표현 불가능 - 메타데이터 부족으로 구조 정의 어려움 | - 데이터 구조가 대량일 경우, 사람이 읽기에 복잡할 수 있음 - 스키마 검증 필요 | - 파일의 크기 거대 - 파싱 속도가 느림 |
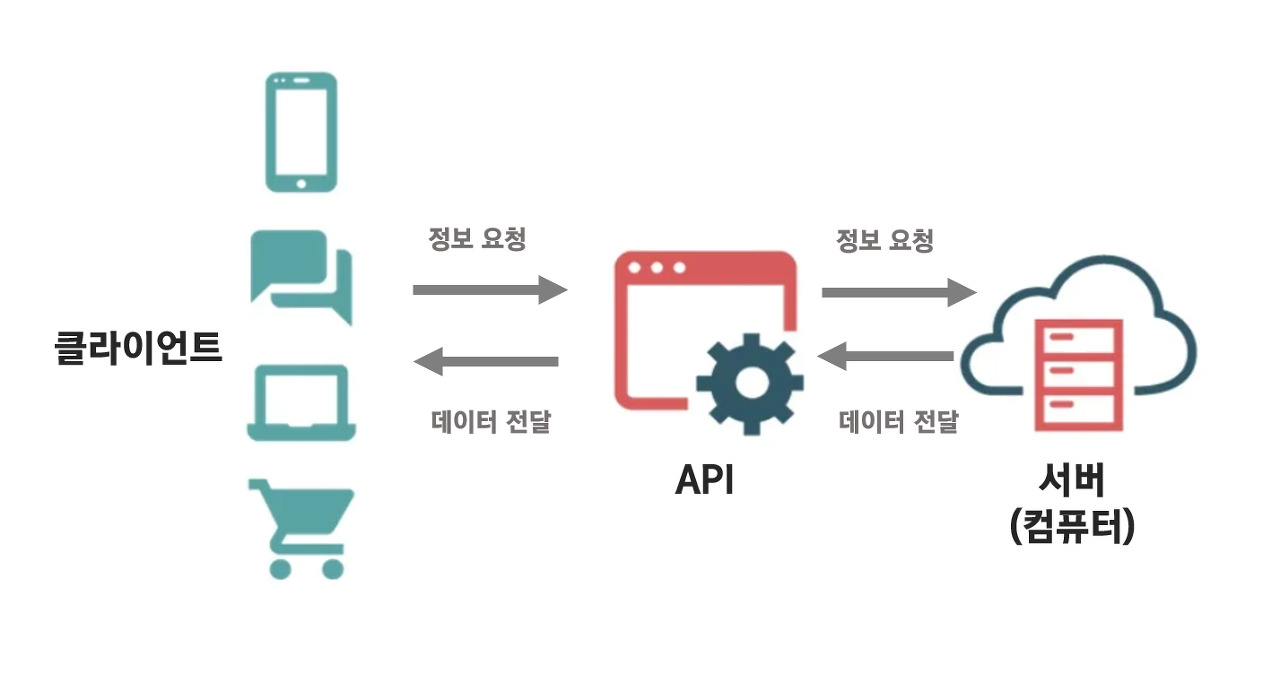
Open API(Application Programming Interface)
웹 사이트에서 서비스를 제공해주는 주체가 자신이 가진 기능을 이용할 수 있도록 공개한 프로그래밍 인터페이스
예시
- 네이버 뉴스
- 백과사전
- 지도
- 구글
API와 Open API 비교
| 항목 | API | Open API |
|---|---|---|
| 접근 권한 | 제한적 (인증 및 권한 필요) | 공개 (인증 키만 있으면 접근 가능) |
| 보안 수준 | 매우 높음 | 비교적 낮음 |
| 사용 목적 | 금융, 비즈니스 등과 같은 민감한 데이터 수집 | 공공 데이터 및 서비스 확장 |
| 데이터 품질 | 보장됨 | 데이터 품질이 다소 낮을 수 있음 |
| 활용 예시 | 기업 내부 시스템 연동, 분석 도구 | 공공 데이터 활용한 연구 및 트렌드 분석, 크롤링 대체 |
웹 크롤링과 Open API 비교
| 항목 | 웹 크롤링 | Open API |
|---|---|---|
| 데이터 접근 방식 | HTML 소스에서 직접 추출 | 구조화된 API 엔드포인트 활용 |
| 데이터 형식 | 비정형 (HTML, 텍스트 등) | 정형 (JSON, XML) |
| 속도 및 효율성 | 느림, 서버 부하 발생 가능 | 빠름, 효율적 |
| 법적 문제 | 이용 약관 위반 가능 | 공식적으로 허용된 데이터 사용 |
| 유지 보수 | 페이지 구조 변경 시 수정 필요 | 제공자가 데이터 구조 관리 |
| 활용 예시 | 뉴스 기사, 쇼핑몰 정보 수집 | 공공 데이터, 소셜 미디어 분석 |
공공 데이터 API
- 대한민국 정부가 주도하는 공공데이터 개방 플랫폼
- 다양한 정부 기관과 공공기관에서 보유한 데이터를 누구나 접그할 수 있도록 공개
- 다양한 주제의 데이터셋을 CSV, Excel, JSON, XML 등의 형식으로 무료로 다운로드 가능
- 기상청, 보건복지부, 교통API 등 API 형태로 데이터를 제공하여, 실시간 데이터 접근 가능
Reference
- https://tech.kakaoenterprise.com/157
- https://developer-together.tistory.com/49
- https://www.etoday.co.kr/news/view/1821057
- https://casit.co.kr/67
- https://www.qrcsolutionz.com/certification/gdpr
- https://www.playsw.or.kr/artificial/textbook/detail/38
- https://www.mk.co.kr/news/it/10804558
- https://slownews.kr/72658
- https://m.blog.naver.com/ifb0901/222495654935
- https://techtodays.weebly.com/home/understanding-overfitting-in-machine-learning-balancing-precision-and-generalization
- https://steemit.com/kr/@doctorbme/doctorbme-essay-bias-variance
- https://brunch.co.kr/@saetae/101
- https://john-analyst.medium.com/smote로-데이터-불균형-해결하기-5ab674ef0b32
- https://datascienceschool.net/03 machine learning/14.02 비대칭 데이터 문제.html
- https://gdsc-university-of-seoul.github.io/Imbalanced-data/
- https://imbalanced-learn.org/stable/auto_examples/combine/plot_comparison_combine.html#sphx-glr-auto-examples-combine-plot-comparison-combine-py
- https://casa-de-feel.tistory.com/15
- https://stackabuse.com/guide-to-parsing-html-with-beautifulsoup-in-python/
- https://testgrid.io/blog/selenium-webdriver/
- https://velog.io/@zxzz45/API
- https://www.data.go.kr/index.do
This post is licensed under CC BY 4.0 by the author.