데이터 전처리
데이터 전처리
정형 데이터 전처리
- 데이터셋 : Kaggle Wine Reviews Dataset
데이터프레임 불러오기
1 2 3
import pandas as pd df = pd.read_csv('winemag-data_first150k.csv')
수치형 데이터 전처리
결측치 처리
결측치 확인
1 2
print("결측치 개수 확인:") print(df.isnull().sum())
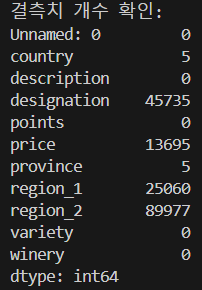
결측치 제거
1 2 3
df_dropna = df.dropna() print("\n결측치 제거 후 데이터프레임(df_dropna):") print(df_dropna)
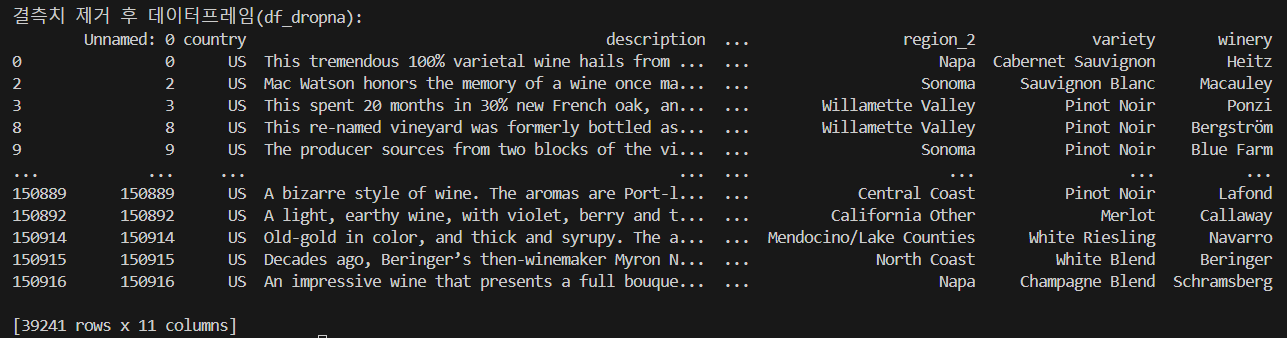
결측치 대체(Imputation) 방법(평균·중앙값·고유값 등)도 고려해야 함
예시 :df['price'].fillna(df['price'].mean())
이상치 탐지 및 제거
시각화
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
import seaborn as sns import matplotlib.pyplot as plt fig, axes = plt.subplots(1, 2, figsize=(12, 5)) # 왼쪽 그래프: points 분포 sns.histplot(data=df, x='points', bins=10, ax=axes[0]) axes[0].set_title('Distribution of Wine Points') # 오른쪽 그래프: price 분포 sns.histplot(data=df, x='price', bins=20, ax=axes[1]) axes[1].set_title('Distribution of Wine Price') # 그래프 간 간격 조절 plt.tight_layout() plt.show()
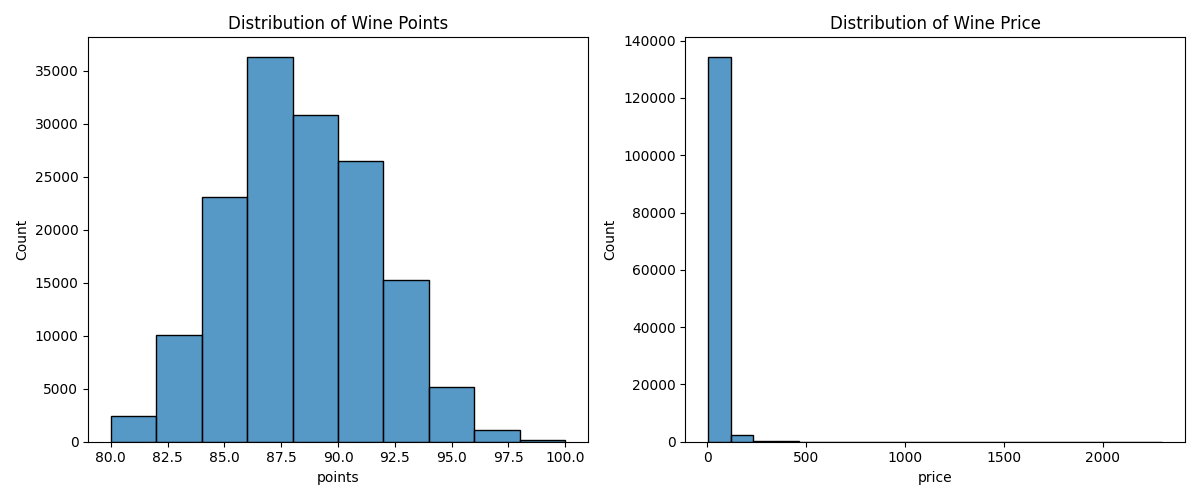
- 이상치 처리
price열을 기준으로, IQR(Interquartile Range) 방법을 사용하여 이상치를 탐지하고 제거- Lower Bound = Q1 - (1.5 * IQR)
- Upper Bound = Q3 + (1.5 * IQR)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
df_iqr = df_dropna.copy() # Step 1) IQR 계산 Q1 = df_iqr['price'].quantile(0.25) Q3 = df_iqr['price'].quantile(0.75) IQR = Q3 - Q1 lower_bound = Q1 - 1.5 * IQR upper_bound = Q3 + 1.5 * IQR print("Q1 =", Q1) print("Q3 =", Q3) print("IQR =", IQR) print("Lower Bound =", lower_bound) print("Upper Bound =", upper_bound) # Step 2) 이상치 마스킹 mask = (df_iqr['price'] < lower_bound) | (df_iqr['price'] > upper_bound) outliers = df_iqr[mask] # 이상치만 모아보기 print("\n이상치 개수:", len(outliers)) # Step 3) 이상치 제거 df_iqr_cleaned = df_iqr[~mask] # 이상치가 아닌(정상 범위) 데이터만 남김 print("\n이상치 제거 전 데이터 크기:", df_iqr.shape) print("이상치 제거 후 데이터 크기:", df_iqr_cleaned.shape)

이상치 제거 결과
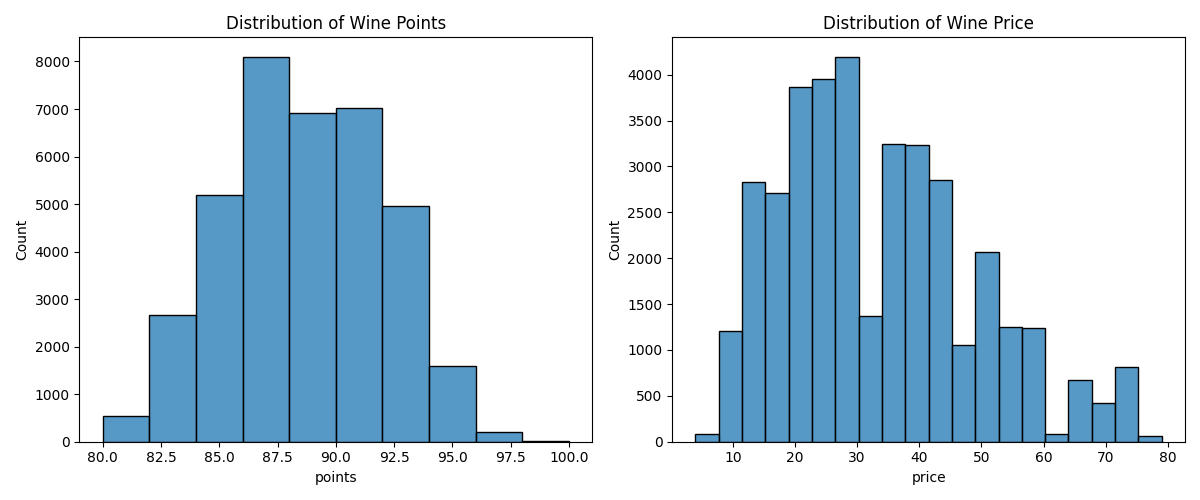
스케일링 및 정규화
사이킷런에서 제공하는 스케일링 함수
방법 설명 사용 용도 StandardScaler 평균을 제거하고 분산을 조정하여 단위 분산으로 표준화 (Z-점수 정규화) 정규 분포를 따른다고 가정할 때 유리하며, 선형 모델에서 자주 사용 MinMaxScaler 최소값을 0, 최대값을 1로 변환하여 모든 값을 [0, 1] 범위로 맞춤 특성의 범위가 크게 다를 때, 간단히 0~1 사이로 조정하고 싶을 때 유용 MaxAbsScaler 각 특성의 최대 절댓값으로 스케일링 (데이터에서 음수값이 없을 때는 MinMaxScaler와 유사) 희소 데이터나 음수가 없는 데이터에서 사용 RobustScaler 중앙값(median)과 IQR(사분위수 범위)를 사용해 스케일링 (이상치 영향 최소화) 이상치가 많은 데이터에서, 이상치 영향 줄이고 싶을 때 사용 Normalizer 샘플(행)별로 단위 노름(유클리디안 노름 등)을 사용해 벡터 크기가 1이 되도록 정규화 (텍스트 데이터 등에 주로 사용) 방향이 중요한 경우, 예: 문서 유사도 계산 때(각 행이 한 샘플, 열은 단어) MinMaxScaler 적용
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
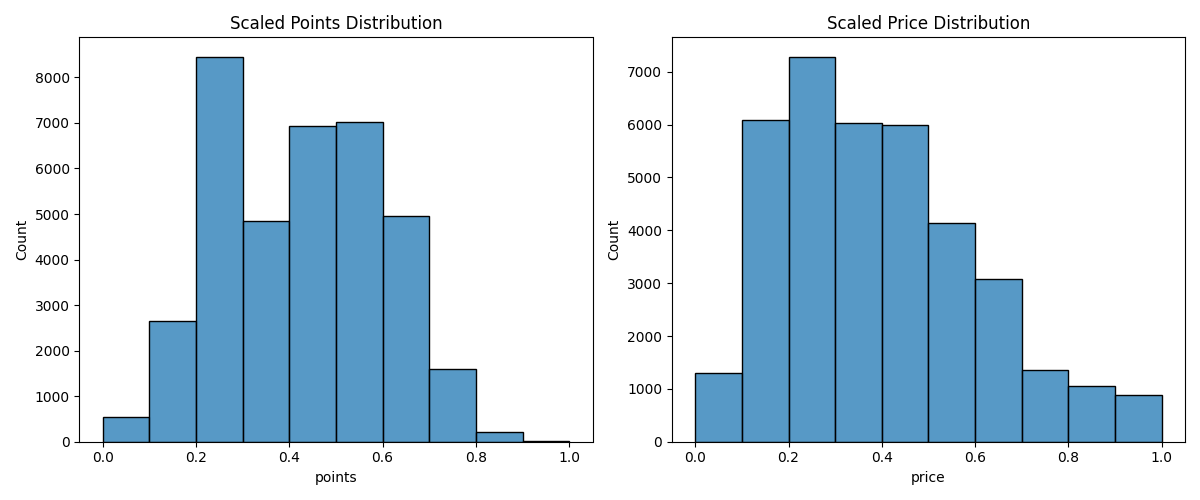
# 스케일링 (MinMaxScaler) 적용 # - 'points'와 'price'만 스케일링한다고 가정 (다른 수치형 컬럼 있으면 추가 가능) numeric_columns = ['points', 'price'] scaler = MinMaxScaler() scaled_data = scaler.fit_transform(df_iqr_cleaned[numeric_columns]) # 스케일링 결과를 새로운 DataFrame으로 scaled_df = pd.DataFrame(scaled_data, columns=numeric_columns) # 원본(범주형 등) + 스케일링된 수치형 결합 df_others = df_iqr_cleaned.drop(columns=numeric_columns) result_df = pd.concat([scaled_df, df_others], axis=1) print("\n최종 전처리 완료 데이터프레임(result_df) info:") print(result_df.head(10)) # 간단 시각화 fig, axes = plt.subplots(1, 2, figsize=(12, 5)) sns.histplot(data=result_df, x='points', bins=10, ax=axes[0]) axes[0].set_title('Scaled Points Distribution')
범주형 데이터 전처리
데이터 타입 변환
- 많은 머신러닝 알고리즘(선형/로지스틱 회귀, 결정 트리, 신경망 등)은 수치형 입력만 처리
- 범주형 데이터(명목형, 순서형)를 그대로 사용하면 연산이 불가능하거나, 잘못된 결과를 초래할 수 있음
country= ‘France’, ‘US’, ‘Italy’ 같은 텍스트 상태
→ 모델에서는 단순 문자열 비교만 가능
→ 명확한 수치 값으로 변환해야 함
순서형 데이터
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import pandas as pd
# 임시 데이터프레임: 품질등급(quality) - 순서가 존재한다고 가정
data = {
'wine_id': [101, 102, 103, 104, 105],
'review_text': [
"Light body, slightly acidic",
"Balanced flavor, moderate tannins",
"Rich aroma, well-structured palate",
"Very diluted, watery taste",
"Complex, long finish"
],
# 순서형(Ordinal) 범주: Low < Medium < High
'quality': ["Low", "Medium", "High", "Low", "High"]
}
df = pd.DataFrame(data)
print("원본 데이터:")
print(df)
- 초급, 중급, 고급 등 순서가 있는 데이터는 1, 2, 3 등 숫자로 매핑 가능
수동 숫자 매핑
1 2 3 4 5 6
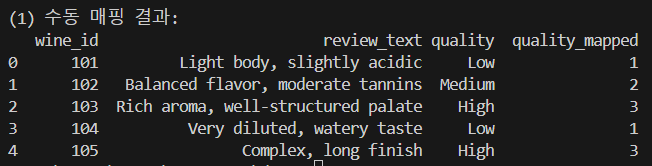
# quality: "Low"=1, "Medium"=2, "High"=3 으로 직접 매핑 mapping = {'Low': 1, 'Medium': 2, 'High': 3} df['quality_mapped'] = df['quality'].map(mapping) print("\n(1) 수동 매핑 결과:") print(df)
사이킷런 OrdinalEncoder
1 2 3 4 5 6 7 8 9 10 11
from sklearn.preprocessing import OrdinalEncoder # OrdinalEncoder는 2차원 배열 형태가 필요. # quality 열만 선택 -> df[['quality']] 로 DataFrame 형태 encoder = OrdinalEncoder(categories=[['Low','Medium','High']]) # 순서: Low(0) < Medium(1) < High(2) df['quality_encoded'] = encoder.fit_transform(df[['quality']]) print("\n(2) OrdinalEncoder 결과:") print(df)

명목형 데이터
country,variety등의 국가나 품종을 나타내는 컬럼은 one-hot Encoding을 통해 변환 가능판다스 get_dummies()
1 2 3 4 5 6
categorical_cols = ['country'] # get_dummies()로 원-핫 인코딩 df_encoded = pd.get_dummies(df, columns=categorical_cols, drop_first=True) print(df_encoded.head())

country_Italy,country_US,country_France… 처럼 각 국가별 컬럼(0/1) 추가
범주가 너무 많으면(예: 국가 종류가 100개가 넘는 경우) 차원의 폭발이 일어날 수 있음
상위 N개 국만 다루거나 차원 축소 기법을 고려해야 함
비정형 데이터 전처리
텍스트 데이터 전처리
- 비정형 텍스트 데이터는 띄어쓰기, 문장부호, 대소문자, 불용어(의미가 없는 단어) 등 다양한 형태로 존재
- 텍스트 전처리 과정을 통해 데이터의 잡음을 제거하고, 분석·모델링에서 효율적인 형태로 변환하는 것이 핵심
결측치 처리
1
2
3
4
5
# 와인 리뷰 데이터 로드
df = pd.read_csv('winemag-data_first150k.csv')
# 결측치 처리
df_dropna = df.dropna(subset=['description'])
문장 부호 제거
- 문장 부호(?!.,~ 등)는 분석에 중요한 의미가 없는 경우가 많아 제거
- 단, What? vs What! 처럼 문장 부호가 감정을 표현한다면 그대로 둬야 할 수도 있음 (도메인 고려)
string.punctuation은 파이썬 내장:!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
대소문자 통일
- 일반적으로 영문 텍스트는 소문자로 통일하여 토큰 일관성을 높임
- 한국어의 경우는 보통 형태소 분석 단계에서 소문자 변환을 굳이 안 할 수도 있음
1
2
3
4
text = "Hello World! This is an Example."
text_lower = text.lower()
print(text_lower)
# hello world! this is an example.
불용어(Stopwords) 제거
- 분석에 의미가 거의 없는 단어(예: 영어의 “the”, “a”, “an”… / 한국어의 조사, 접속사 등)
- 도메인에 따라 어떤 단어를 불용어로 볼지 결정
- 한국어의 경우, 형태소 분석 후 조사·어미(예: “은”, “는”, “이”, “가” 등) 제거를 불용어 제거로 볼 수 있음
1
2
3
stopwords = ["the", "a", "an", "to", "of", "and", "in"]
def remove_stopwords(tokens):
return [t for t in tokens if t not in stopwords]
어간 추출(Stemming) 또는 표제어(Lemmatization) 추출
- 어간 추출(Stemming): 규칙 기반으로 접미사, 변형을 단순히 자름
- 표제어 추출(Lemmatization): 단어의 품사, 문법적 역할을 고려하여 실제 사전에 있는 형태로 반환
- 속도: Stemming > Lemmatization
- 정확도: Lemmatization > Stemming (단어 의미를 더 잘 보존)
1
2
3
4
5
6
7
8
9
10
11
12
from nltk.stem import PorterStemmer, WordNetLemmatizer
import nltk
nltk.download('wordnet')
nltk.download('omw-1.4') # Lemmatizer를 위해 필요
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
word = "studies"
print("Stemming:", stemmer.stem(word)) # "studi"
print("Lemmatization:", lemmatizer.lemmatize(word)) # "study"
한국어 텍스트 전처리
형태소 분석기(Okt, Mecab, etc.)
- Okt(Open Korean Text), Mecab, Komoran 등 다양한 라이브러리가 존재
- 형태소 분석: 문장을 형태소(단어 + 조사/접미사 등) 단위로 분리
- 품사 태깅(pos): 형태소와 함께 품사 태그를 반환
- 명사 추출(nouns): 텍스트에서 명사만 뽑아내기
1
2
3
4
5
6
7
8
from konlpy.tag import Okt
okt = Okt()
sentence = "아 이 영화 진짜 재미없다... 시간아까움"
print("morphs:", okt.morphs(sentence))
print("pos:", okt.pos(sentence))
print("nouns:", okt.nouns(sentence))
- 출력
- morphs:
['아', '이', '영화', '진짜', '재미없다', '...', '시간', '아까움'] - pos:
[('아', 'Ex'), ('이', 'Noun'), ('영화', 'Noun'), ...] - nouns:
['이', '영화', '시간']- 불용어 제거
- morphs:
- 불용어 사전(예: ‘의’, ‘가’, ‘이’, ‘은’, ‘는’, ‘에’, ‘들’, ‘하다’, ‘되다’ 등)을 별도로 지정
- 형태소 분석 후 나온 결과에서 불용어 사전에 포함된 단어 제거
1
2
3
4
5
6
7
stopwords_ko = ['이', '은', '는', '...',
'하다', '되다', '도'] # 예시
tokens = okt.morphs(sentence) # ['아', '이', '영화', '진짜', '재미없다', '...', '시간', '아까움']
cleaned_tokens = [t for t in tokens if t not in stopwords_ko]
print(cleaned_tokens)
# 예: ['아', '영화', '진짜', '재미없다', '시간', '아까움']
This post is licensed under CC BY 4.0 by the author.