데이터 증강
데이터 증강
데이터 증강(Data Augmentation)
개념
- 기존 데이터를 변형하거나 가공하여 새로운 데이터를 생성하는 기법
- 데이터의 양과 다양성을 증가시켜 모델 성능을 향상시킴
- 예시
이미지

텍스트

필요성
- 머신러닝과 딥러닝 모델의 성능을 향상시키기 위해 필수적인 기술
데이터가 충분하지 않으면 AI 모델이 학습할 패턴이 제한되어 새로운 데이터에서 낮은 정확도를 보일 수 있음
- 불균형 데이터
- 특정 클래스에 대한 훈련 데이터가 작을 때 생기는 문제
- 모델이 빈도가 높은 다수 클래스에 편향되어 예측 결과가 왜곡될 수있음
- 소수 클래스 데이터를 증강하여 데이터 비율을 맞춰 해결 가능
- 모델 과적합
- 모델이 학습 데이터에만 특화되어 일반화 성능 저하
- 데이터 증강을 통해 데이터 다양성을 증가시켜 다양성을 방지
- 예시
딥러닝 기반 의료영상 분석을 위한 데이터 증강 기법

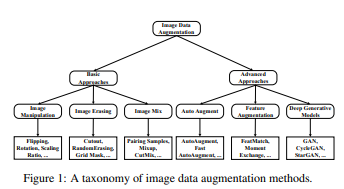
이미지 데이터 증강
이미지 데이터 기본 구조
- 이미지 데이터는 픽셀로 구성된 2D 또는 3D 행렬로, 각 픽셀은 색상 정보를 포함
픽셀
- 이미지를 구성하는 가장 작은 단위
- 한 개의 이미지에 픽셀이 많을수록 고화질
- 해상도
- 이미지의 세로 픽셀 수와 가로 픽셀 수의 곱으로 표현
- 예시 : 1920x1080, 1280x1024
GrayScale
- 단일 채널로 구성
- 각 픽셀은 명암 정보를 나타냄
- 값의 범위
- 0: 완전한 검정
- 255: 완전한 흰색
- 중간 값은 회색 톤을 나타냄
- 명암 표현
- 이진화된 이미지(0과 1)로만 표현할 경우 명암 차이를 나타내기 어려움
- 그레이스케일은 0~255 범위의 값으로 더 세밀한 명암을 표현
- 변환 방법
- RGB 이미지를 그레이스케일로 변환 시, 각 픽셀의 R, G, B 값을 가중 평균하여 단일 값으로 변환
- 일반적인 변환 식
Gray = 0.2989 * R + 0.5870 * G + 0.1140 * B- 인간의 시각이 녹색에 더 민감하고, 파랑에 덜 민감한 점을 반영한 결과
- 활용
- 이미지 분석에서 계산 복잡성을 줄이기 위해 컬러 이미지를 그레이스케일로 변환하여 처리
- 얼굴 인식, 엣지 검출 등 명암 정보가 중요한 작업에 유용
RGB
- 구조
- RGB는 빨강(Red), 녹색(Green), 파랑(Blue) 세 가지 색상의 조합으로 색을 표현
- 각 색상 채널은 0~255 범위의 값을 가지며, 이 조합으로 다양한 색상을 표현
- 특징
- 각 채널은 독립적인 2D 행렬로 저장되며, 결합하여 3D 행렬 형태의 이미지를 구성
- 예시 : 6x5 크기의 이미지는 (높이)x(너비)x(채널)의 3D 배열로 표현
- 색상 표현 방식
- (255, 0, 0): 순수 빨강
- (0, 255, 0): 순수 녹색
- (0, 0, 255): 순수 파랑
- (255, 255, 255): 흰색
- (0, 0, 0): 검정
- 활용
- 컬러 이미지 데이터 분석의 기본 형태로, 객체 인식, 이미지 분류 등에 사용
HSV
- 구성 요소
- 색상(Hue)
- 색의 종류를 나타내며, 0~360도로 표현
- 0: 빨강, 120: 녹색, 240: 파랑
- 채도(Saturation)
- 색의 진하기를 나타내며, 0~1 범위로 표현
- 값이 0에 가까울수록 흐릿하고, 1에 가까울수록 선명함
- 명도(Value)
- 색의 밝기를 나타내며, 0~1 범위로 표현
- 값이 0이면 완전한 검정, 값이 1이면 완전한 밝기
- 색상(Hue)
- 특징
- HSV 모델은 색상 정보와 밝기 정보를 분리하여 색상에 독립적인 처리가 가능
- 인간의 시각적 인지 방식과 더 유사하여 이미지 분석 및 처리에 유리
- 활용
- 객체 추적, 색상 기반 분할, 이미지 필터링 등 색상 정보가 중요한 작업에서 활용
이미지 데이터셋
- MNIST
- 손글씨 숫자로 구성된 흑백 이미지 데이터셋으로, 숫자(0~9) 클래스를 포함
- 딥러닝 초보 학습용으로 자주 사용
- CIFAR-10
- 10개의 클래스(예: 비행기, 자동차, 새 등)로 구성된 컬러 이미지 데이터셋
- 딥러닝 모델의 성능 비교 및 검증에 자주 사용
이미지 데이터 증강 기법
- 과적합을 피하기 위해 생성을 통해 증강
- 하나의 이미지를 이용하여 다양한 이미지를 생성할 수 있음
이미지 데이터 로드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import cv2
import numpy as np
from matplotlib import pyplot as plt
# 이미지 로드
img_path = 'profile.jpg' # Colab에 이미지를 업로드한 뒤 경로를 입력
img = cv2.imread(img_path)
# OpenCV는 기본적으로 BGR 포맷을 사용하므로, 시각화를 위해 RGB로 변환
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 시각화 함수
def show_image(image, title='Image'):
plt.imshow(image)
plt.title(title)
plt.axis('off')
plt.show()
# 원본 이미지 확인
show_image(img_rgb, title="Original Image")

이미지 조작(Image Manipulation)
- 플리핑(Flipping)
- 이미지를 좌우 또는 상하로 뒤집음
대칭적인 패턴 학습 강화 및 모델 강건성 향상
1 2 3 4 5 6 7
# 좌우 플리핑 flipped_img_lr = cv2.flip(img_rgb, 1) # 좌우 플리핑 show_image(flipped_img_lr, title="Left-Right Flipped") # 상하 플리핑 flipped_img_ud = cv2.flip(img_rgb, 0) # 상하 플리핑 show_image(flipped_img_ud, title="Up-Down Flipped")

- 회전(Rotation)
- 이미지를 일정 각도로 회전
객체의 방향 변화에 대한 모델 적응력 강화
1 2 3 4 5 6
# 회전 (h, w) = img_rgb.shape[:2] center = (w // 2, h // 2) matrix = cv2.getRotationMatrix2D(center, 45, 1.0) # 45도 회전 rotated_img = cv2.warpAffine(img_rgb, matrix, (w, h)) show_image(rotated_img, title="Rotated 45 Degrees")

- 확대/축소(Scaling)
- 이미지를 확대하거나 축소하여 다양한 크기의 객체를 처리하도록 학습
다양한 크기의 객체를 처리할 수 있는 모델 생성
1 2 3 4 5 6
# 크기 변경 (확대 및 축소) resized_img_up = cv2.resize(img_rgb, None, fx=1.5, fy=1.5, interpolation=cv2.INTER_LINEAR) # 확대 show_image(resized_img_up, title="Scaled Up (1.5x)") resized_img_down = cv2.resize(img_rgb, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_LINEAR) # 축소 show_image(resized_img_down, title="Scaled Down (0.5x)")


- 이동(Translation)
- 이미지를 수평 또는 수직으로 이동
위치 변화에 민감하지 않은 모델 학습
1 2 3 4 5
# 이동 (Translation) tx, ty = 50, 30 # x축 50px, y축 30px 이동 translation_matrix = np.float32([[1, 0, tx], [0, 1, ty]]) translated_img = cv2.warpAffine(img_rgb, translation_matrix, (w, h)) show_image(translated_img, title="Translated (50px, 30px)")

- 색상 변환(Color Jittering)
색조, 채도, 밝기 등을 변경하여 색상 변화에 강건한 모델을 학습
1 2 3 4 5 6 7 8
# 색상 변화 (Color Jittering) brightness = 50 img_bright = cv2.convertScaleAbs(img_rgb, beta=brightness) # 밝기 증가 show_image(img_bright, title="Brightened Image (+50 Brightness)") contrast = 1.5 img_contrast = cv2.convertScaleAbs(img_rgb, alpha=contrast) # 대비 증가 show_image(img_contrast, title="High Contrast Image (1.5x Contrast)")


- 노이즈 추가(Adding Noise)
- 이미지에 랜덤 노이즈를 추가하여 잡음에 견고한 모델 생성
노이즈에 민감하지 않은 강건한 모델 학습
1 2 3 4
# 노이즈 추가 noise = np.random.normal(0, 25, img_rgb.shape).astype(np.uint8) # 평균 0, 표준편차 25 noisy_img = cv2.add(img_rgb, noise) show_image(noisy_img, title="Image with Noise")

- 잘라내기(Cropping)
- 이미지의 특정 영역을 선택하여 잘라냄
객체 중심의 학습 데이터 생성 및 배경의 영향 최소화
1 2 3 4 5
# 잘라내기 (Cropping) x_start, y_start = 50, 50 x_end, y_end = w - 50, h - 50 cropped_img = img_rgb[y_start:y_end, x_start:x_end] show_image(cropped_img, title="Cropped Image")
영역 삭제
- Cutout
- 이미지의 특정 영역을 정사각형 형태로 삭제
- 삭제된 영역은 일반적으로 0 또는 평균 픽셀 값으로 채워짐
모델이 삭제된 영역 외의 정보를 학습하도록 유도하여 과적합을 방지
1 2 3 4 5 6 7 8 9 10 11
# Cutout 적용 h, w, _ = img.shape x = np.random.randint(0, w // 2) y = np.random.randint(0, h // 2) cutout_size = 50 img_cutout = img.copy() img_cutout[y:y+cutout_size, x:x+cutout_size] = 0 # 결과 출력 show_image(cv2.cvtColor(img_cutout, cv2.COLOR_BGR2RGB), title="Cutout Image")

- Random Erasing
- Cutout의 변형된 방식
- 삭제 영역의 크기, 위치, 모양이 랜덤하게 설정
다양한 삭제 패턴을 학습하여 모델의 강건성을 높임
1 2 3 4 5 6 7 8 9 10 11 12
# Random Erasing 적용 img_random_erasing = img.copy() for _ in range(3): # 랜덤하게 3개 영역 삭제 x = np.random.randint(0, w) y = np.random.randint(0, h) rect_w = np.random.randint(10, 50) rect_h = np.random.randint(10, 50) img_random_erasing[y:y+rect_h, x:x+rect_w] = np.random.randint(0, 256) # 결과 출력 show_image(cv2.cvtColor(img_random_erasing, cv2.COLOR_BGR2RGB), title="Random Erasing Image")
이미지 혼합
- Mixup
- 두 이미지를 픽셀 단위로 혼합하여 새로운 이미지를 생성
- 레이블 또한 두 이미지의 비율에 따라 혼합
모델이 다중 클래스 분포를 학습하도록 유도
1 2 3 4 5
# Mixup lambda_val = 0.7 img2 = cv2.flip(img_rgb, 1) # 두 번째 이미지를 좌우 플리핑한 것으로 사용 mixup_img = cv2.addWeighted(img_rgb, lambda_val, img2, 1 - lambda_val, 0) show_image(mixup_img, title="Mixup Image")
- CutMix
- 한 이미지의 일부 영역을 잘라내고, 해당 영역에 다른 이미지를 삽입하여 새로운 이미지를 생성
객체 정보와 배경 정보를 혼합 학습
1 2 3 4 5 6
# CutMix x1, y1 = 100, 100 x2, y2 = 200, 200 cutmix_img = img_rgb.copy() cutmix_img[y1:y2, x1:x2] = img2[y1:y2, x1:x2] show_image(cutmix_img, title="CutMix Image")

자동 증강(Auto Augment)
- 자동으로 최적의 증강 방법을 탐색하여 성능을 향상시키는 기법
- 탐색 과정
- 데이터의 특성을 분석하여 최적의 증강 정책을 탐색
- 다양한 증강 기법을 적용한 후, 성능이 가장 좋은 조합을 선택
- 강화 학습 기반 증강 정책 탐색
- 자동 증강은 컨트롤러(Controller)를 통해 증강 정책을 학습하는 과정으로 이루어짐
- 컨트롤러는 RNN(Recurrent Neural Network)을 사용하며, 아래의 과정을 반복
- 정책 샘플링: 컨트롤러가 증강 전략(연산 유형, 확률, 강도)을 샘플링
- 자식 네트워크 학습: 선택된 전략으로 자식 네트워크를 학습시켜 검증 정확도를 계산
- 피드백 전달: 검증 정확도(R)를 컨트롤러에 피드백으로 전달하여 업데이트
- 반복: 컨트롤러가 업데이트된 정책을 바탕으로 새로운 증강 전략을 샘플링
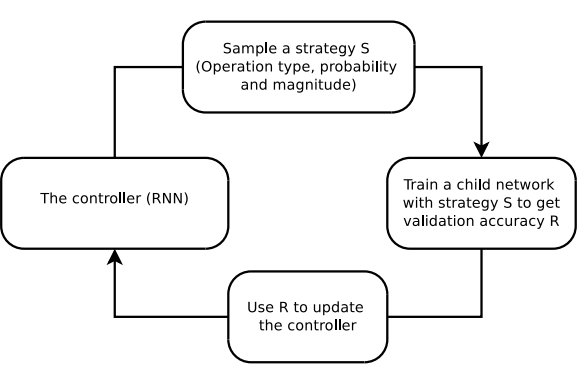
- 장점
- 데이터에 맞춘 최적의 증강 정책을 학습할 수 있음
- 강화 학습으로 증강 조합을 탐색하기 때문에 수작업 조정 불필요
- 주요 알고리즘
- Fast Auto Augment
- 밀도 매칭 기반으로 증강 정책을 효율적으로 탐색하여 시간을 단축
1 2 3 4 5
# AutoAugment 적용 autoaugment_transform = transforms.Compose([ AutoAugment(policy=AutoAugmentPolicy.IMAGENET), transforms.ToTensor() ])

- Population Based Augmentation (PBA)
- 고정된 증강 정책 대신 비정형 증강 정책 스케줄을 생성
- 예 : 하이퍼파라미터 스케줄링 기반으로 증강 기법 탐색
- 고정된 증강 정책 대신 비정형 증강 정책 스케줄을 생성
- RandAugment
- 탐색 과정을 제거하고 간단한 규칙 기반 증강으로 탐색 공간 축소
1 2 3 4 5
# RandAugment 적용 randaugment_transform = transforms.Compose([ RandAugment(num_ops=2, magnitude=9), transforms.ToTensor() ])

- Fast Auto Augment
특징 증강(Feature Augmentation)
- 학습된 특징 공간에서 데이터를 변형하고 보강하여 모델 성능을 개선하는 기법
- 입력 공간에서 이루어지는 전통적인 증강과 달리, 모델의 학습된 특징 공간에서 작업하여 보다 정교한 데이터를 생성
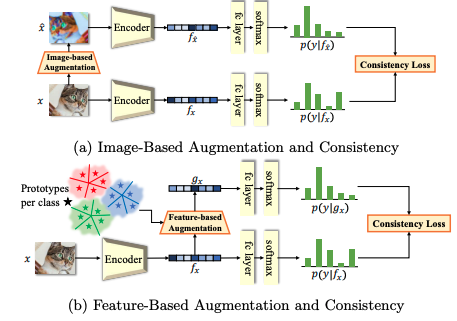
- 과정
- 학습된 특징 벡터를 기반으로 데이터 간의 유사성을 분석
- 특징 벡터를 변형하거나 다른 데이터와 조합하여 새로운 데이터를 생성
- 생성된 데이터를 모델 학습에 활용하여 데이터 다양성을 높이고, 모델의 일반화 성능을 향상
- 주요 알고리즘
- FeatMatch
- 클래스 간 및 클래스 내의 특징 프로토타입을 분석하여 변환
- 방법
- 동일 클래스의 샘플에서 평균 특징 벡터(프로토타입)를 계산
- 프로토타입을 기준으로 데이터를 변형하거나 보강
- 효과
- 데이터 간의 일관성을 유지하면서도 모델 학습에 필요한 데이터 다양성을 제공
- Moment Exchange
- 데이터의 특정 모멘트(moment)를 다른 데이터와 교환하여 새로운 샘플 생성
- 방법
- 두 데이터의 평균(mean)과 표준편차(std)를 계산
- 한 데이터의 특징 벡터를 다른 데이터의 평균과 표준편차로 정규화하여 새로운 데이터를 생성
- 효과
- 현실적인 샘플을 생성하여 모델이 복잡한 데이터 분포를 학습하도록 지원
- FeatMatch
생성 모델 활용
- 데이터 분포를 학습하여 새로운 데이터를 생성하는 방법
- 실제 데이터와 유사한 새로운 샘플을 만들어 모델 성능을 개선하거나 데이터 부족 문제를 해결하는 데 사용
- GAN (Generative Adversarial Networks)
- 두 개의 신경망(생성기와 판별기)이 서로 경쟁하며 학습하는 구조
- 생성기가 판별기를 속일 수 있을 정도로 실제와 유사한 데이터를 생성
- 구조
- 생성기(generator): 새로운 데이터를 생성
- 판별기(discriminator): 생성된 데이터와 실제 데이터를 구별
- 과정
- 생성기는 랜덤 노이즈를 입력으로 받아 데이터를 생성
- 판별기는 생성된 데이터와 실제 데이터를 입력받아 진짜/가짜를 판별
- 생성기는 판별기를 속이도록 학습하며, 판별기는 생성기의 데이터를 정확히 판별하도록 학습
- 주요 GAN 기반 기법
- Pix2Pix
- 이미지-이미지 변환을 위한 GAN
- 입력 이미지를 특정 스타일로 변환
- 위성 사진 변환, 흑백 이미지 컬러화

- CycleGAN
- 입력과 출력 데이터 간에 쌍(pairing)이 필요 없는 이미지 변환 GAN
- 사진에서 그림 스타일로 변환, 계절 변화(여름-겨울)

- 입력과 출력 데이터 간에 쌍(pairing)이 필요 없는 이미지 변환 GAN
- StarGAN
- 다중 도메인 이미지 변환을 지원하는 GAN
- 얼굴 감정 변화, 헤어스타일 변환

- 다중 도메인 이미지 변환을 지원하는 GAN
- StarGAN v2
- 고해상도 다중 도메인 변환을 지원하며, 더 정교한 세부 조정 가능
- 얼굴 속성 편집, 고화질 이미지 변환

- 고해상도 다중 도메인 변환을 지원하며, 더 정교한 세부 조정 가능
- Pix2Pix
텍스트 데이터 증강
텍스트 데이터
- 텍스트 데이터 증강은 자연어 처리 모델의 성능을 높이고 데이터 부족 문제를 해결하기 위해 사용되는 기술
- 텍스트 데이터는 순서 변경, 단어 교체 등에 매우 민감하므로 신중한 접근이 필요
텍스트 데이터의 민감성
- 의미 변화 가능성
- 텍스트 데이터는 단순한 단어 교체나 순서 변경만으로도 의미가 크게 변할 수 있음
- 증강 과정에서 의미를 유지하면서도 데이터 다양성을 확보하는 것이 중요
- 증강 효과
- 모델 성능 향상
- 다양한 텍스트 패턴을 학습하여 자연어 처리 모델의 성능을 개선
- 데이터 부족 문제 해결
- 적은 데이터로도 모델 학습을 가능하게 하여 데이터 수집 비용 절감
- 의미 보존
- 증강 과정에서 원문의 의미를 최대한 유지하도록 설계
- 모델 성능 향상
텍스트 데이터 증강 기법
- 동의어 교체 (Synonym Replacement)
- 문장에서 n개의 단어를 동의어로 교체
- 텍스트의 기본 구조와 의미를 유지하면서도 다양한 표현을 생성
- 예시
- “빠른 여우” -> “신속한 여우”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
! pip install konlpy from konlpy.tag import Okt import random synonym_dict = { "빠른": ["신속한", "재빠른", "날쌘"], "여우": ["수달", "늑대", "너구리"], "뛰어넘었다": ["점프했다", "넘어갔다", "날아올랐다"] } def korean_synonym_replacement(sentence, n): okt = Okt() words = okt.morphs(sentence) for _ in range(n): word_to_replace_index = random.randint(0, len(words) - 1) word_to_replace = words[word_to_replace_index] synonyms = synonym_dict.get(word_to_replace, []) if synonyms: synonym = random.choice(synonyms) words[word_to_replace_index] = synonym return " ".join(words) # 사용 예시 sentence = "빠른 여우가 뛰어넘었다" print(korean_synonym_replacement(sentence, 1))
- 랜덤 단어 추가 (Random Word Insertion)
- 문장의 랜덤한 위치에 관련 단어를 추가하여 다양성을 높임
- 예시
- “여우가 뛰어넘었다” -> “여우가 갑자기 뛰어넘었다”
1 2 3 4 5 6 7 8 9
def random_word_insertion(sentence, word_to_insert): words = sentence.split() insert_position = random.randint(0, len(words)) words.insert(insert_position, word_to_insert) return " ".join(words) # 사용 예시 sentence = "여우가 뛰어넘었다" print(random_word_insertion(sentence, "갑자기"))
- 단어 순서 변경 (Random Word Swap)
- 문장에서 두 단어의 순서를 무작위로 변경
- 텍스트 구조를 약간 변경하여 모델의 일반화 성능을 높임
- 예시
- “여우가 나무를 뛰어넘었다” -> “나무를 여우가 뛰어넘었다”
1 2 3 4 5 6 7 8 9 10
def random_word_swap(sentence): okt = Okt() words = okt.morphs(sentence) idx1, idx2 = random.sample(range(len(words)), 2) words[idx1], words[idx2] = words[idx2], words[idx1] return " ".join(words) # 사용 예시 sentence = "여우가 나무를 뛰어넘었다" print(random_word_swap(sentence))
- 역번역 (Back Translation)
- 문장을 다른 언어로 번역한 뒤 다시 원래 언어로 변환하여 새로운 표현 생성
- 예시
- “여우가 빠르게 움직인다” -> “The fox moves quickly” -> “여우가 신속히 움직인다”
1 2 3 4 5 6 7 8 9 10 11
!pip install googletrans==4.0.0-rc1 from googletrans import Translator def back_translation(sentence, src_lang='ko', tgt_lang='en'): translator = Translator() translated = translator.translate(sentence, src=src_lang, dest=tgt_lang).text return translator.translate(translated, src=tgt_lang, dest=src_lang).text # 사용 예시 sentence = "여우가 빠르게 움직인다" print(back_translation(sentence))
- 마스킹 (Masking)
- 문장의 특정 단어를 가리고 해당 단어를 예측하도록 모델을 학습
- 예시:
- “여우가 [MASK] 뛰어넘었다”
1 2 3 4 5 6 7 8 9
def masking(sentence, mask_token="[MASK]"): words = sentence.split() mask_position = random.randint(0, len(words) - 1) words[mask_position] = mask_token return " ".join(words) # 사용 예시 sentence = "여우가 나무를 뛰어넘었다" print(masking(sentence))
- 대규모 언어 모델 (LLM) 활용
- LLM을 활용하여 다양한 변형된 문장을 생성
- 예시
- “여우가 뛰어넘었다” -> “여우가 큰 점프를 했다”, “여우가 담장을 넘었다”
1 2 3 4 5 6 7 8 9 10 11 12 13 14
!pip install transformers from transformers import pipeline def generate_variations(prompt): # Hugging Face에서 지원하는 텍스트 생성 모델 로드 generator = pipeline('text-generation', model='gpt2') outputs = generator(prompt, max_length=50, num_return_sequences=3) return [output['generated_text'] for output in outputs] # 사용 예시 prompt = "여우가 뛰어넘었다" variations = generate_variations(prompt) for variation in variations: print(variation)
시계열 데이터 증강
시계열 데이터의 특성
- 시간 의존성
- 시계열 데이터는 시간의 흐름에 따라 데이터 간 관계가 형성
- 시간 순서를 바꾸거나 제거하면 데이터의 의미가 손상될 수 있음
- 주요 적용 사례
- 금융 데이터 (주식 가격, 환율 등)
- 센서 데이터 (IoT, 스마트 공장)
- 의료 데이터 (심전도, 혈압 기록)
- 기상 데이터 (온도, 강수량 등)
시계열 데이터 증강 기법
Time Domain
- 시간 도메인에서 직접적으로 데이터를 변형하는 방법
- 크로핑 (Cropping)
- 시계열 데이터의 특정 구간을 잘라내어 새로운 데이터를 생성
- 예시
- 원본 데이터: [1, 2, 3, 4, 5, 6]
- 크로핑 결과: [2, 3, 4]
1 2 3 4 5 6
def crop_time_series(data, start, end): return data[start:end] # 사용 예시 data = [1, 2, 3, 4, 5, 6] print(crop_time_series(data, 1, 4))
- 플리핑 (Flipping)
- 데이터를 뒤집어 시간 순서를 반대로 변환
- 예시
- 원본 데이터: [1, 2, 3, 4, 5, 6]
- 플리핑 결과: [6, 5, 4, 3, 2, 1]
1 2 3 4 5 6
def flip_time_series(data): return data[::-1] # 사용 예시 data = [1, 2, 3, 4, 5, 6] print(flip_time_series(data))
- 지터링 (Jittering)
- 데이터에 랜덤 노이즈를 추가하여 변형
- 예시
- 원본 데이터: [1, 2, 3, 4, 5]
- 지터링 결과: [1.1, 1.9, 3.05, 3.95, 5.2]
1 2 3 4 5 6 7 8 9
import numpy as np def jitter_time_series(data, noise_level=0.1): noise = np.random.normal(0, noise_level, len(data)) return data + noise # 사용 예시 data = np.array([1, 2, 3, 4, 5]) print(jitter_time_series(data))
- 위상 변환 (Time Warping)
- 데이터의 시간 축을 비선형적으로 늘리거나 줄임
- 예시
- 원본 데이터: [1, 2, 3, 4, 5]
- 위상 변환 결과: [1, 1.5, 2, 3, 5]
1 2 3 4 5 6 7 8 9 10
import numpy as np def time_warp(data, factor=0.5): indices = np.arange(0, len(data), factor) indices = np.round(indices).astype(int) return data[indices] # 사용 예시 data = np.array([1, 2, 3, 4, 5]) print(time_warp(data, factor=0.5))
Frequency Domain
- 주파수 도메인에서 변형하여 데이터를 생성하는 방법
- 푸리에 변환 (Fourier Transform)
- 데이터를 주파수 성분으로 변환하여 특정 주파수를 강조하거나 제거한 후 역변환
- 예시
- 원본 데이터: [1, 2, 3, 4, 5]
- 주파수 강조 후: [1.2, 2.1, 3.0, 4.1, 5.2]
1 2 3 4 5 6 7 8 9 10
import numpy as np def fourier_transform(data): freq = np.fft.fft(data) freq[2:] = 0 # 특정 주파수만 남김 return np.fft.ifft(freq).real # 사용 예시 data = np.array([1, 2, 3, 4, 5]) print(fourier_transform(data))
분해 기반 방법 (Decomposition-Based Methods)
시계열 데이터를 추세(Trend), 계절성(Seasonality), 잔차(Residual)로 분해한 후 각 요소를 개별적으로 변형하여 새로운 시계열 데이터를 생성
1 2 3 4 5 6 7 8 9 10 11 12 13 14
from statsmodels.tsa.seasonal import seasonal_decompose import numpy as np def decompose_time_series(data, freq=12): decomposition = seasonal_decompose(data, period=freq) trend = decomposition.trend seasonal = decomposition.seasonal residual = decomposition.resid return trend, seasonal, residual # 사용 예시 data = np.random.rand(120) trend, seasonal, residual = decompose_time_series(data) print(trend, seasonal, residual)
딥러닝 모델 활용
GAN (Generative Adversarial Networks)을 활용하여 새로운 시계열 데이터를 생성
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
import torch import torch.nn as nn class TimeSeriesGAN(nn.Module): def __init__(self): super(TimeSeriesGAN, self).__init__() self.generator = nn.Sequential( nn.Linear(100, 256), nn.ReLU(), nn.Linear(256, 256), nn.Tanh() ) def forward(self, noise): return self.generator(noise) # 사용 예시 gan = TimeSeriesGAN() noise = torch.randn(10, 100) generated_data = gan(noise) print(generated_data)
자동화된 증강 기법
강화 학습 또는 메타러닝을 활용하여 데이터 증강 전략을 자동으로 학습하는 기법
1 2 3 4 5 6 7 8 9 10 11 12 13 14
from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split def automated_augmentation(X, y): # 데이터를 자동 증강하는 간단한 예제 model = RandomForestClassifier() X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) model.fit(X_train, y_train) print("Accuracy:", model.score(X_test, y_test)) # 사용 예시 (더미 데이터) X = np.random.rand(100, 10) y = np.random.randint(0, 2, 100) automated_augmentation(X, y)
Reference
- https://www.ibm.com/kr-ko/topics/data-augmentation
- https://cm.asiae.co.kr/article/2024062515565724185
- https://jksronline.org/DOIx.php?id=10.3348/jksr.2020.0158
- https://arxiv.org/abs/2204.08610
- https://arxiv.org/abs/1805.09501
- https://arxiv.org/abs/2007.08505
- https://learnopencv.com/paired-image-to-image-translation-pix2pix/
- https://junyanz.github.io/CycleGAN/
- https://arxiv.org/abs/1711.09020
- https://arxiv.org/abs/1912.01865
- https://sodayeong.tistory.com/6
This post is licensed under CC BY 4.0 by the author.