데이터 EDA
데이터 EDA
데이터 EDA(Exploratory Data Analysis)
- 데이터를 본격적으로 분석하기 전에 데이터를 탐색하고 이해하는 과정
- 데이터의 분포, 특성, 이상치, 결측치 등 데이터 품질에 영향을 미치는 요인을 파악하는데 핵심적인 단계
정형 데이터 EDA
- 단계
- 데이터프레임의 각 컬럼과 값 확인하기
- 결측지 확인
- 기술 통계(평균, 중앙값, 최대값, 최소값, 분산, 표준편차, 사분위수)
- 데이터 분포 확인(히스토그램, 커널밀도, 박스 플롯)
- 상관관계 분석
- 데이터의 스케일링 필요성 검토
- 파생 변수 생성 가능성 탐색
- 데이터셋 : Kaggle Students’ Academic Performance Dataset
데이터프레임 불러오기
1
2
3
import pandas as pd
df = pd.read_csv('xAPI-Edu-Data.csv')
데이터프레임의 각 컬럼과 값 확인하기
df.columns
- 데이터프레임의 컬럼명을 한눈에 확인할 수 있음
1
df.columns
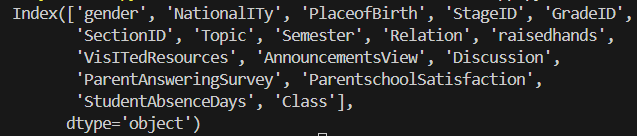
컬럼명이 많을 때, 별도로 목록을 확인해두면 이후 전처리나 EDA에 용이
df.head()와 df.tail()
df.head()는 데이터프레임의 앞에서 5개 행을 기본으로 보여줌df.tail()는 데이터프레임의 뒤에서 5개 행을 기본으로 보여줌- 파라미터로 숫자를 넣으면, 그만큼의 행을 확인 가능
df.head(8)→ 앞에서 8개 행df.tail(4)→ 뒤에서 4개 행
1
2
3
4
5
# 앞부분 확인 (기본 5개 행)
df.head()
# 뒷부분 확인 (기본 5개 행)
df.tail()


결측지 확인
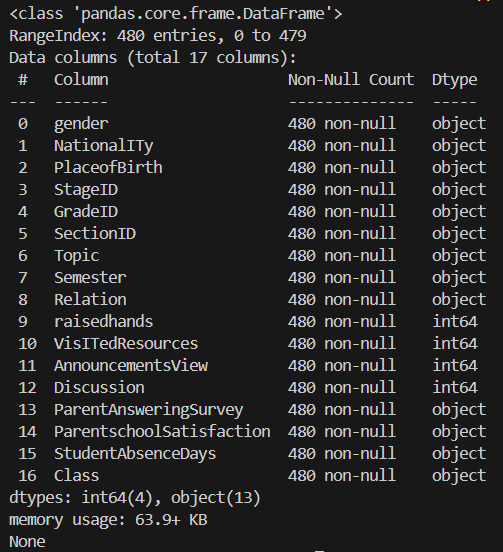
df.info()
- 데이터프레임의 전체적인 정보를 확인
- 각 컬럼의 데이터 타입, Null(결측치) 여부, 메모리 사용량 등을 파악할 수 있음
1
df.info()
기술 통계(평균, 중앙값, 최대값, 최소값, 분산, 표준편차, 사분위수)
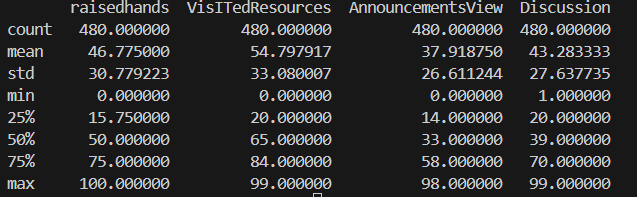
df.describe()
- 수치형(numerical) 데이터에 대해 기본적인 통계량(평균, 표준편차, 최소값, 최대값, 사분위수 등)을 제공
- 범주형(카테고리) 데이터는 기본적으로 제외되지만,
df.describe(include='all')을 사용하면 범주형 변수 정보도 일부 확인 가능 - 수치형 컬럼을 빠르게 파악할 수 있으며, 이상치(Outlier) 등도 어느 정도 가늠 가능
1
df.describe()
데이터 분포 확인(히스토그램, 커널밀도, 박스 플롯)
- 수치형 데이터와 범주형 데이터에 따라 분포 확인 방법이 다름
| 대분류 | 소분류 | 예시 |
|---|---|---|
| 수치형 데이터 | 연속형 데이터 | 키, 몸무게, 수입 |
| 이산형 데이터 | 과일 개수, 책 페이지 개수 | |
| 범주형 데이터 | 순서형 데이터 | 학점, 순위(랭킹) |
| 명목형 데이터 | 성별, 음식 종류, 우편 번호 |
수치형 데이터
- 일정 범위 안에서 어떻게 분포하고 있는지 파악하는 것이 중요
| 시각화 그래프 | 특징 |
|---|---|
| 히스토그램 | - 데이터가 특정 값에 집중되어 있는지, 고르게 분포되어 있는지, 또는 한쪽으로 치우쳐 있는지 등을 쉽게 파악 - 이상치 탐지나 데이터의 범위, 중앙 경향 등을 확인하는 데도 유용 |
| 커널밀도추정 (KDE) | - 히스토그램보다 분포를 부드럽게 시각화하며, 데이터의 연속적인 밀도 변화를 표현 - 특정 구간에 얼마나 데이터가 집중되어 있는지, 여러 개의 봉우리가 있는지 등을 쉽게 확인할 수 있음 |
| 박스플롯 | - 데이터의 중앙값(Median)과 사분위수(1Q, 3Q), 그리고 이상치(Outlier)를 한눈에 보여주는 시각화 도구 - 데이터의 분포, 변동성, 중심 경향을 빠르게 파악 가능하며, 특히 이상치를 식별하는 데 매우 유용 |
| 바이올린플롯 | - 박스플롯과 커널 밀도 추정(KDE)을 결합한 그래프로, 데이터의 분포(밀도)와 박스플롯 정보를 동시에 보여줌 - 폭이 넓은 구간은 데이터가 밀집된 부분을 의미하며, 분포 모양을 직관적으로 파악할 수 있음 |
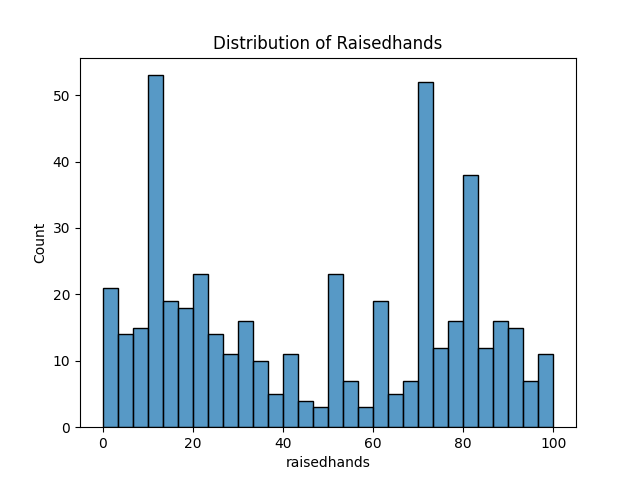
- 히스토그램 (histplot)
- 막대(bar)를 통해 특정 구간(bin)에 데이터가 몇 개 분포하는지 보여줌
- 데이터가 특정 값에 치우쳐 있는지(편향 여부), 또는 고르게 분포되어 있는지(균등 분포) 쉽게 파악할 수 있음
- 해석
- 막대가 왼쪽에 몰려 있으면 오른쪽 꼬리가 긴 분포(Right-skewed)
- 막대가 오른쪽에 몰려 있으면 왼쪽 꼬리가 긴 분포(Left-skewed)
- 막대가 비교적 고르게 분포한다면 균등 분포(Uniform distribution)
- 중앙에 몰려 종 모양이면 정규분포(Normal distribution)로 추정 가능
1 2 3 4 5 6 7
import seaborn as sns import matplotlib.pyplot as plt # raisedhands 컬럼의 히스토그램 sns.histplot(data=df, x='raisedhands', bins=30) # bins로 구간 개수 조정 plt.title('Distribution of Raisedhands') plt.show()
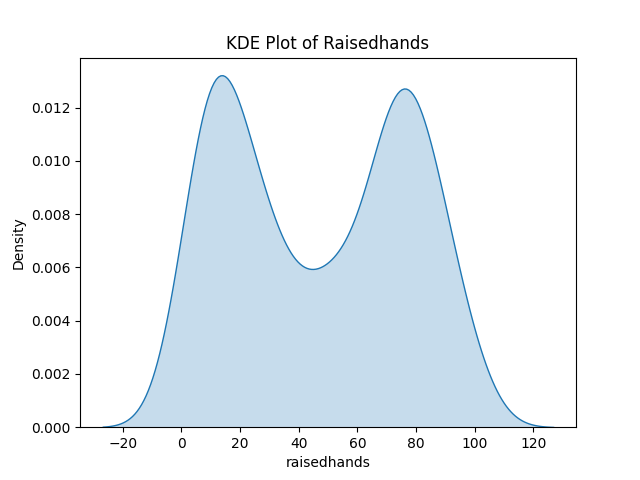
- 커널 밀도 추정 (kdeplot)
- 히스토그램보다 더 부드럽게 분포 형태를 파악할 수 있도록 도와줌
- 데이터가 어느 구간에서 많이 몰려 있는지, 가장 빈도가 높은 구간은 어디인지 등을 곡선 형태로 나타냄
- 해석
- 봉우리(peak)가 높은 부분일수록 해당 값에 데이터가 밀집
- 꼬리(tail)가 어느 쪽으로 길게 늘어져 있는지 확인하여 분포의 치우침(skewness) 파악
1 2 3
sns.kdeplot(data=df, x='raisedhands', shade=True) # shade=True로 면적 음영 추가 plt.title('KDE Plot of Raisedhands') plt.show()
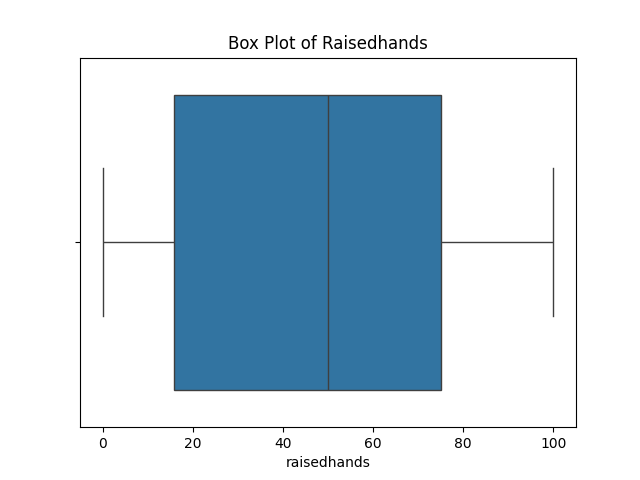
- 박스플롯 (boxplot)
- 데이터의 중앙값(median), 사분위수(1Q, 3Q), 그리고 이상치(Outlier) 등을 한눈에 확인할 수 있음
- 사분위수를 통해 데이터가 어떻게 퍼져 있는지, 그리고 극단값이 어디에 위치하는지를 파악할 수 있음
- 해석
- 박스의 아랫부분(1사분위수, Q1)과 윗부분(3사분위수, Q3)
- 박스 내부의 굵은 선이 중앙값(median)
- 상하단의 수염(whisker)은 보통 ±1.5 IQR(사분위 범위)을 나타냄
- 수염 밖의 점들은 이상치(Outlier) 로 간주
1 2 3
sns.boxplot(data=df, x='raisedhands') plt.title('Box Plot of Raisedhands') plt.show(
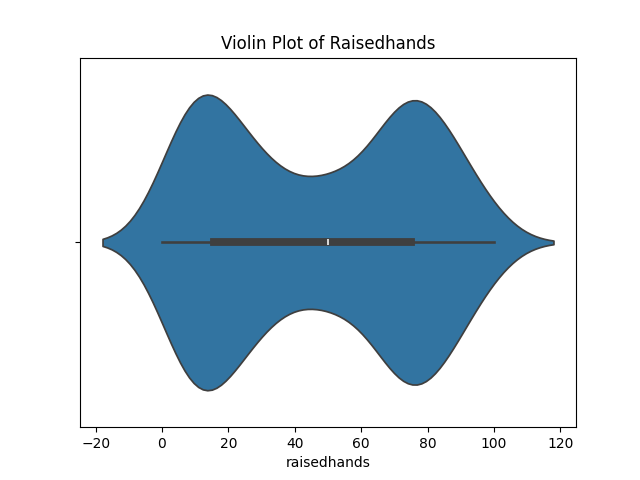
- 바이올린플롯 (violinplot)
- 박스플롯 + KDE(커널밀도)를 합친 형태로, 데이터 분포의 밀도까지 한 번에 확인 가능
- 값이 많이 모여 있는 곳은 폭이 넓게, 적은 곳은 폭이 좁게 표
- 해석 방법
- 중앙의 하얀 점이 중앙값
- 두께(폭)가 두꺼울수록 해당 구간에 데이터가 많다는 의미
- 박스플롯보다 분포 형태를 직관적으로 파악하기 쉽다
1 2 3
sns.violinplot(data=df, x='raisedhands') plt.title('Violin Plot of Raisedhands') plt.show()
범주형 데이터
- 개수를 세어 빈도(frequency)를 시각화하는 방식을 주로 사용
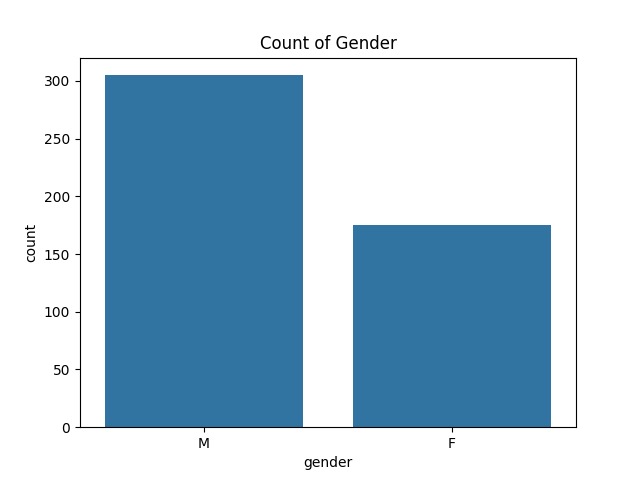
- 카운트플롯 (countplot)
- 특정 범주(카테고리)가 몇 개 있는지 막대 그래프로 표현
- 해석
- M(남성)과 F(여성)의 데이터 개수 비교
1 2 3
sns.countplot(data=df, x='gender') plt.title('Count of Gender') plt.show()
범주가 많을 경우
sns.countplot(data=df, y='NationalITy')처럼 y축에 배치하기도 함
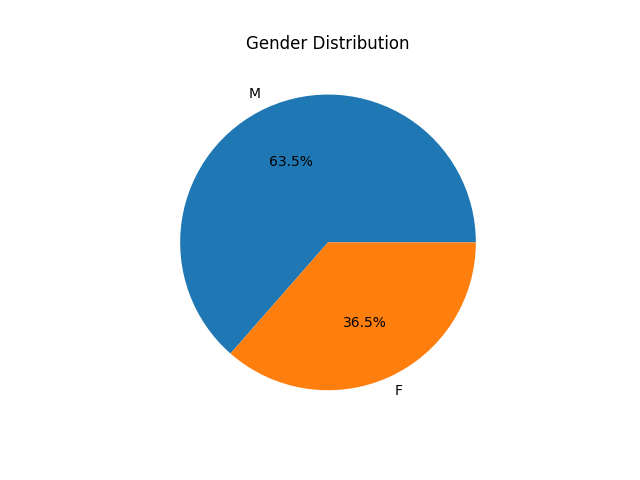
- 파이 차트 (pie chart)
- 전체 대비 각 범주의 비율을 시각적으로 확인할 때 유용함
- pandas의
value_counts()혹은 matplotlib/seaborn을 이용해 간단히 그릴 수 있음 - 해석
- M과 F가 전체에서 각각 몇 % 차지하는지 비율 확인
- 범주가 여러 개일 때 비율 비교가 직관적
1 2 3 4
df['gender'].value_counts().plot(kind='pie', autopct='%1.1f%%') plt.title('Gender Distribution') plt.ylabel('') # 불필요한 y축 레이블 제거 plt.show()
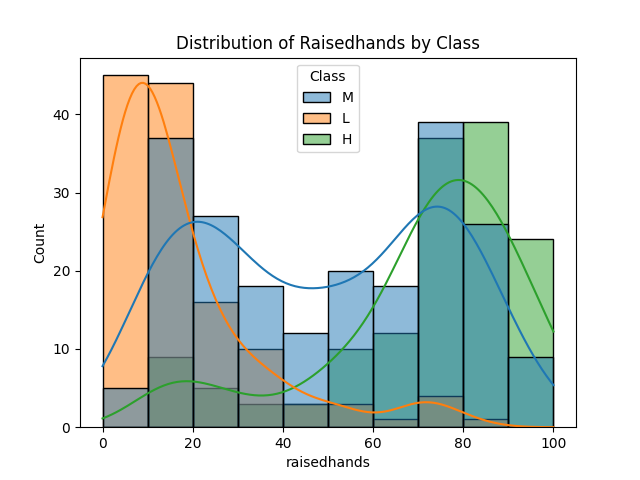
수치형 데이터와 범주형 데이터의 분포를 함께 시각화
- raisedhands & class 시각화
- 히스토그램 + 범주(hue) 사용
- 한 번에 범주(class)가 L(낮음), M(보통), H(높음) 일 때의 분포 차이를 살펴볼 수 있음
- 해석
- 성적이 높은 학생(H)일수록 손을 많이 드는 경향이 있는지
- 성적이 낮은 학생(L)일수록 손을 상대적으로 적게 드는지
- 혹은 특정 구간(예: 300번 이상의 손 들기)에 이상치로 보이는 학생이 존재하는지 등을 직관적으로 확인 가능
1 2 3
sns.histplot(data=df, x='raisedhands', hue='Class', kde=True) # kde=True로 커널밀도 포함 plt.title('Distribution of Raisedhands by Class') plt.show()
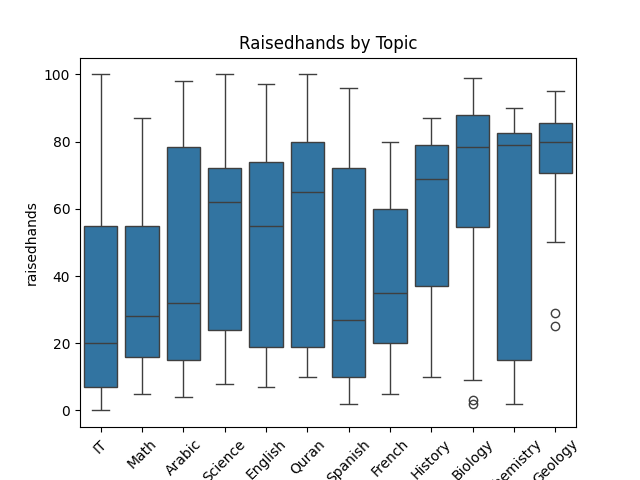
- 히스토그램 + 범주(hue) 사용
- raisedhands & Topic 시각
박스플롯으로 범주형 변수를 x축(또는 y축)에 두고, 수치형 변수를 y축(또는 x축)으로 설정하면
각 범주(과목)마다 손 들기 횟수가 어떻게 분포되어 있는지 한눈에 알 수 있음
예시 해석
- 어떤 과목(Topic)에서 학생들이 대체로 손을 많이 들었는지(중앙값이 높은지)
- 이상치(Outlier)가 어느 과목에서 두드러지는지
- 예: IT 수업을 듣는 학생들의 중앙값이 매우 낮다면, 질문을 덜 한다거나 학습 참여도가 낮을 가능성을 의심해볼 수 있음
- 반대로 Biology나 Chemistry 수업에서 박스플롯의 사분위 범위(IQR)가 넓거나 중앙값이 높다면, 학생들이 질문(손 들기)을 많이 하거나 참여도 차이가 큰 과목일 수도 있음
1 2 3 4
sns.boxplot(data=df, x='Topic', y='raisedhands') plt.title('Raisedhands by Topic') plt.xticks(rotation=45) # 과목명이 많으므로 라벨을 기울여서 표시 plt.show()
상관관계 분석
- 수치형 데이터만 가능
- 변수들 사이 연관성 확인 가능
- 예측 모델에서 중요 변수 식별 시 유용
- 다중공선성 문제를 조기에 발견하여 불필요하거나 중복된 변수 제거
- 피어슨 상관계수 등을 이용하여 각 변수 쌍의 선형성을 값으로 반환
- 값의 범위: 1 ~ 1
- 0에 가까울수록 무상관(관계가 거의 없음)
- +1에 가까울수록 강한 양의 상관 (한 변수가 증가하면 다른 변수도 증가)
- -1에 가까울수록 강한 음의 상관 (한 변수가 증가하면 다른 변수는 감소)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 1) 수치형 컬럼만 추출 (예: number 타입)
numeric_columns = df.select_dtypes(include='number').columns
# 2) 상관계수 행렬 계산
correlation_matrix = df[numeric_columns].corr()
# 3) 히트맵으로 시각화
plt.figure(figsize=(6, 4))
sns.heatmap(correlation_matrix,
annot=True, # 상관계수를 숫자로 표시
cmap='Purples', # 컬러맵
fmt=".2f") # 소수점 둘째 자리까지 표시
plt.title("Correlation Heatmap of Numeric Variables")
plt.show()
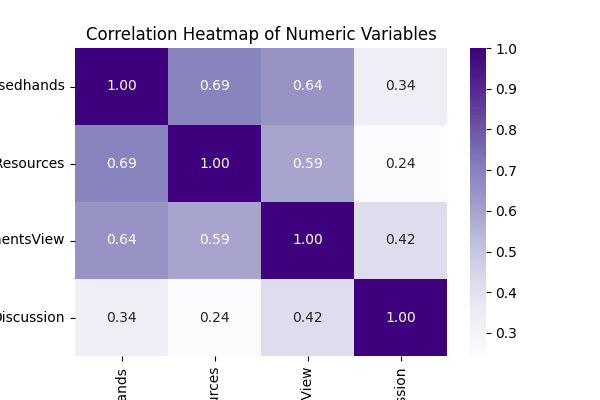
결측치가 있으면
.corr()계산 시 자동으로 제외될 수 있음
데이터의 스케일링 필요성 검토
- 서로 다른 수치형 변수들의 값 범위를 일정한 수준으로 맞추는 작업
- describe() 메서드로 평균, 표준편차, 최댓값 등을 확인하거나, 박스플롯/히스토그램 등을 통해 분포를 시각적으로 비교해보고 결정
- 가중치(계수)가 한쪽으로 치우치는 문제를 방지
- 기울기 기반 모델(선형 회귀, 로지스틱 회귀, SVM, KNN 등)에서 학습 효율 향상
- 종류
- 표준화(standardization)
- 정규화(min-max normalization)
- 로버스트 스케일러(Robust Scaler)
| 스케일링이 필요한 경우 | 스케일링이 필요 없는 경우 |
|---|---|
| 1. 변수의 평균이 크게 다를 때 | 1. 이미 비슷한 범위와 단위를 가지고 있는 변수들인 경우 |
| 2. 데이터의 범위(최솟값~최댓값)가 서로 크게 다를 때 | 2. 트리 기반 모델(예: 랜덤 포레스트, 의사결정나무) 사용하는 경우 (스케일 차이에 크게 영향받지 않음) |
| 3. 한 변수에 이상치(Outlier)가 많아서 데이터 분포가 한쪽으로 치우쳐 있을 때 | 3. 범주형 변수 (스케일링 대상 아님) |
| 4. 변수가 사용하는 단위가 서로 다를 때 | |
| 5. 변수별로 분포가 크게 달라서 비대칭 분포를 보일 때 |
파생 변수 생성 가능성 탐색
- 원본 데이터에서 새로운 의미를 가지도록 가공하거나 결합하여 만든 변수
- 원본 데이터의 정보를 재구성하여 새로운 관점에서 분석 가능
| 데이터 유형 | 파생 변수 예시 | 기대 효과/의도 |
|---|---|---|
| 기상 데이터 | 체감온도 지수, 비 오는 날 여부, 미세먼지 지수 등 | 단순 기온만으로는 설명하기 어려운 실제 체감 환경 반영 |
| 구매 이력 | 월별 구매 횟수, 최근 구매일로부터의 일수(Recency), 평균 결제 금액 등 | LTV(LifeTime Value) 예측, 마케팅 타겟팅 고도화 |
| 리뷰 텍스트 | 리뷰 길이(review_length), 문장 수, 감정 점수(sentiment_score) | 리뷰가 길고 부정적인 키워드를 많이 포함할수록 불만이 큰 고객일 가능성이 높음을 파악 |
| 웹 로그 분석 | 페이지 체류 시간, 방문 빈도, 전환율(conversion rate) | 사용자 행동 패턴(이탈/구매/재방문) 파악, 개인화 추천 알고리즘에 활용 |
| 날짜·시간 데이터 | 요일(주중/주말), 월(계절), 공휴일 여부 등 | 주말 매출, 특정 프로모션 일자 효율 등 비즈니스 인사이트 도출 |
비정형 데이터 EDA
- 단계
- 데이터프레임의 각 컬럼과 값 확인하기
- 결측지 확인
- 데이터 분포 확인(히스토그램, 커널밀도, 박스 플롯)
- 데이터 중복값 확인
- 데이터셋 : Kaggle Wine Reviews Dataset
데이터프레임 불러오기
1
2
3
import pandas as pd
df = pd.read_csv('winemag-data_first150k.csv')
데이터프레임의 각 컬럼과 값 확인하기

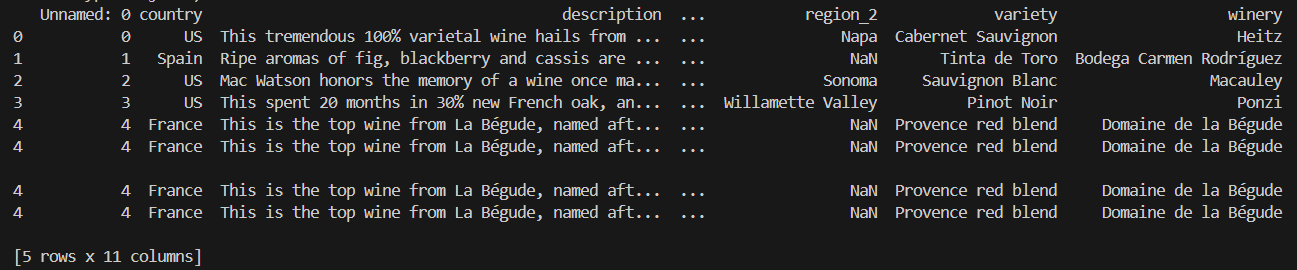

결측지 확인
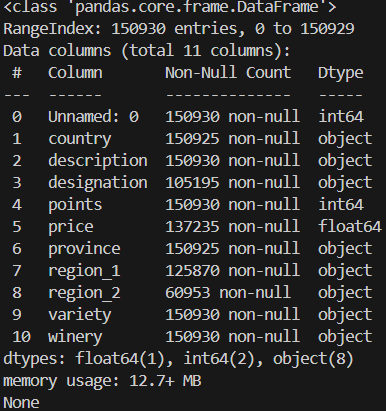
데이터 분포 확인
문장 길이 및 평균 길이 확인
- 텍스트 데이터의 구조 이해
- 데이터의 특성을 파악하거나 모델 입력 값을 조정할 때 유용
1
2
3
4
5
6
7
8
9
10
11
12
#문장 길이를 측정하여 새로운 컬럼(sentence_length)에 저장하고, **평균값** 및 **분포**를 확인
df['description'] = df['description'].fillna('')
# 문장 길이 계산 (문자 수)
df['sentence_length'] = df['description'].apply(len)
# 히스토그램 시각화
sns.histplot(data=df, x='sentence_length', bins=30)
plt.title("Distribution of Sentence Length")
plt.xlabel("Sentence Length (Characters)")
plt.ylabel("Frequency")
plt.show()
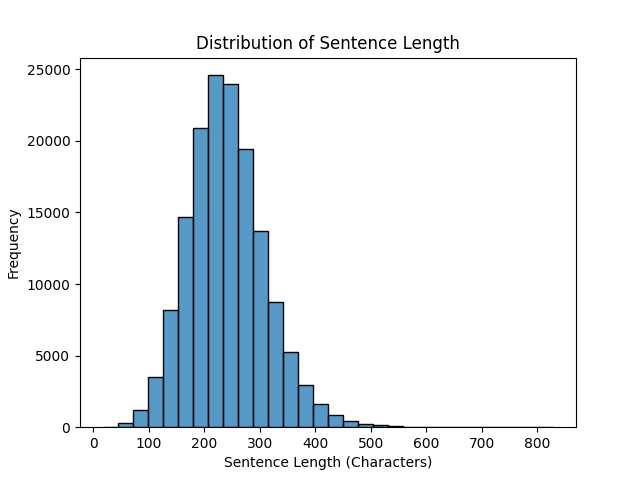
중복값 확인
- 분석 결과의 왜곡을 초래할 수 있으므로 제거하거나 처리하는 것이 중요함
- 중복값의 분포를 직관적으로 확인하기 위해 히트맵을 사용할 수 있음
- 중복값이 특정 구간에서 집중적으로 발생하는지를 확인 가능
1
2
3
4
5
6
7
8
9
10
11
12
13
# duplicated() 메서드를 사용해 텍스트 데이터에서 중복된 행을 찾
duplicates = df[df.duplicated(subset='description', keep=False)]
num_duplicates = df.duplicated(subset='description').sum()
print(f"중복된 텍스트 개수: {num_duplicates}")
# 중복 텍스트 확인
duplicates.head()
# 히트맵 시각화
sns.heatmap(df[['description']].duplicated(subset='description').to_frame(), cbar=False)
plt.title("Duplicate Text Heatmap")
plt.show()


This post is licensed under CC BY 4.0 by the author.