[모두를 위한 딥러닝 시즌2] Lab-10-3 visdom
[모두를 위한 딥러닝 시즌2] Lab-10-3 visdom
Visdom
설치
1
pip install visdom
서버 실행
1
python -m visdom.server
localhost:8097 에 접속해서 확인 가능
Python에서 사용하기
1
2
import visdom
vis = visdom.Visdom()
서버가 꺼져있으면 에러가 발생한다
가능하면 서버를 먼저 실행해두자
Text
1
vis.text("Hello, world!",env="main")
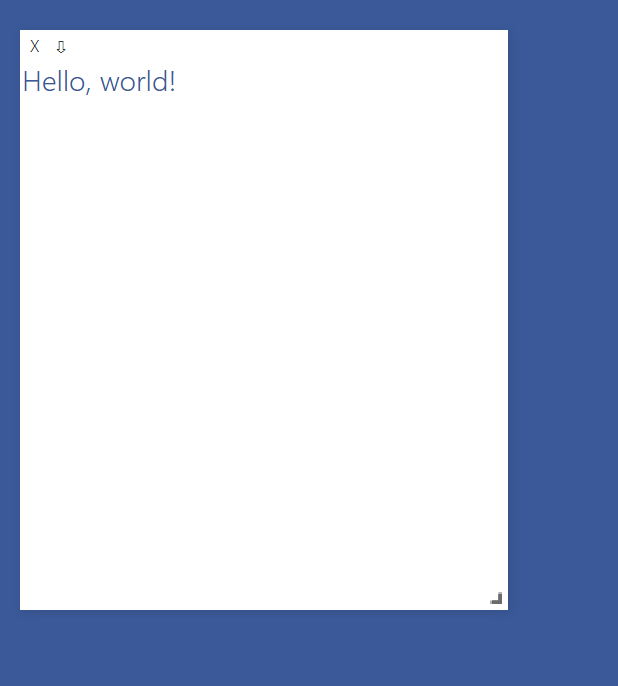
env는 각 독립된 환경을 관리하는데 사용
아래와 같이 visdom 객체에 선언도 가능
1
2
vis = visdom.Visdom(env="main")
vis.text("Hello, world!")
env=”main” 인 창을 모두 종료
1
2
# 종료
vis.close(env="main")
Image
1
2
a=torch.randn(3,200,200)
vis.image(a)

- (C, H, W) 형태
- 여러 이미지를 표시 : (N, 3, H, W)
1
vis.images(torch.Tensor(3,3,28,28))
using MNIST and CIFAR10
- MNIST: 손글씨 숫자(0-9)를 포함한 28x28 픽셀의 흑백 이미지 데이터셋으로, 주로 이미지 분류 모델의 기본 학습용으로 사용
- CIFAR-10: 10개의 다양한 클래스(예: 비행기, 자동차, 새 등)를 포함한 32x32 픽셀의 컬러 이미지 데이터셋으로, 객체 분류와 인식 모델의 학습에 자주 사용
1
2
MNIST = dsets.MNIST(root="./MNIST_data",train = True,transform=torchvision.transforms.ToTensor(), download=True)
cifar10 = dsets.CIFAR10(root="./cifar10",train = True, transform=torchvision.transforms.ToTensor(),download=True)
오류 : RuntimeError: ./MNIST_data/MNIST/processed/training.pt is a zip archive (did you mean to use torch.jit.load()?)
해결 : pip install –upgrade torch torchvision
1
2
3
4
5
6
7
8
9
data = cifar10.__getitem__(0)
print(data[0].shape)
# torch.Size([3, 32, 32])
vis.images(data[0],env="main")
data = MNIST.__getitem__(0)
print(data[0].shape)
# torch.Size([1, 28, 28])
vis.images(data[0],env="main")

Check dataset
1
2
3
4
5
6
for num, value in enumerate(data_loader):
value = value[0]
print(value.shape)
# torch.Size([32, 1, 28, 28])
vis.images(value)
break

Line Plot
1
2
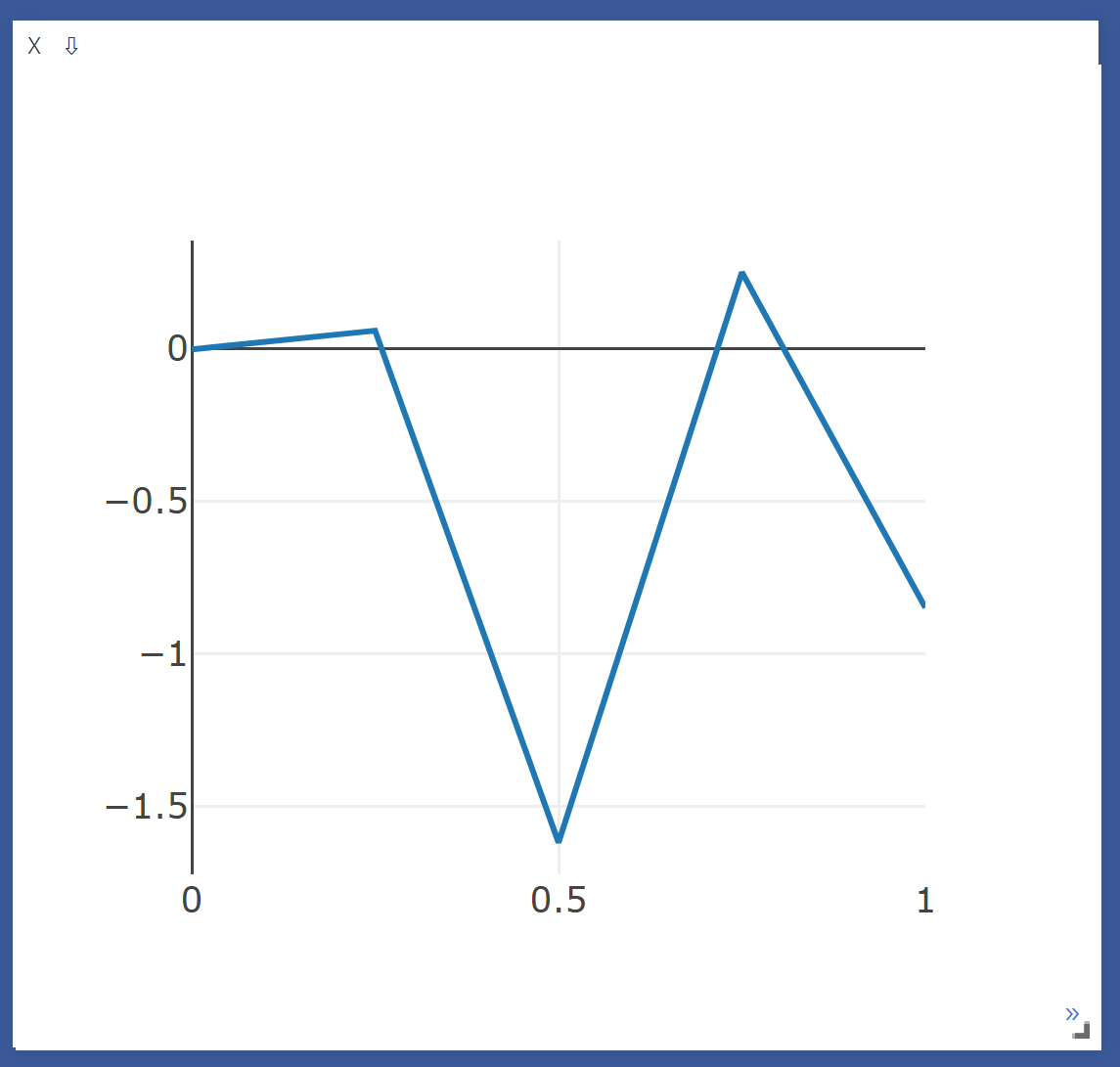
Y_data = torch.randn(5)
plt = vis.line (Y=Y_data)
- x축을 넣지 않으면 0~1 범위로 선언
1
2
X_data = torch.Tensor([1,2,3,4,5])
plt = vis.line(Y=Y_data, X=X_data)
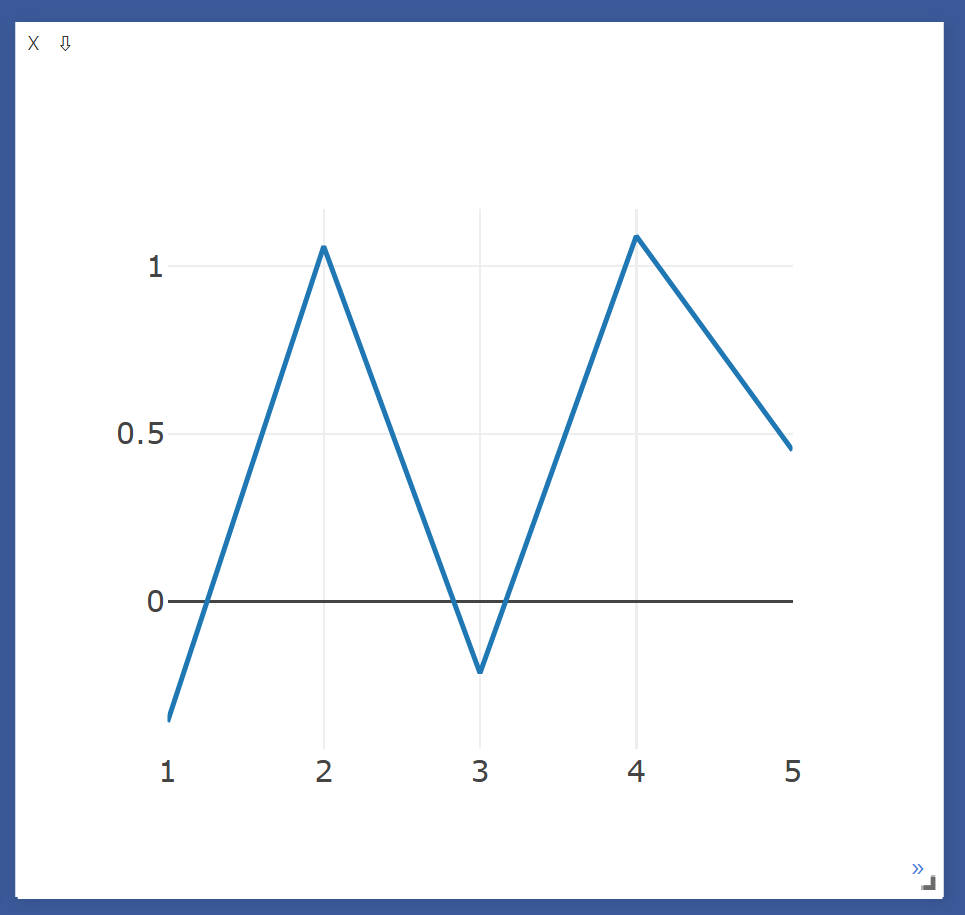
Line update
1
2
3
4
Y_append = torch.randn(1)
X_append = torch.Tensor([6])
vis.line(Y=Y_append, X=X_append, win=plt, update='append')
- x 와 loss 값 업데이트
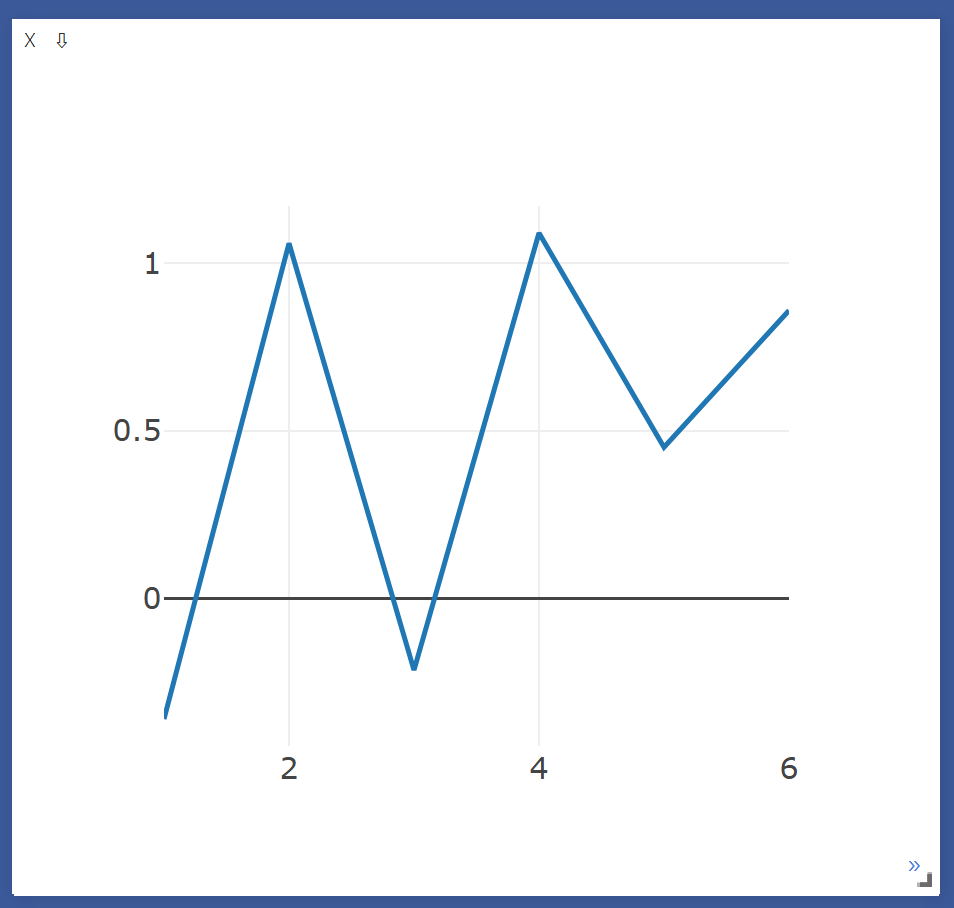
multiple Line on single windows
1
2
3
4
5
num = torch.Tensor(list(range(0,10)))
num = num.view(-1,1)
num = torch.cat((num,num),dim=1)
plt = vis.line(Y=torch.randn(10,2), X = num)
- Y랑 같은 Shape를 가지는 index(X) 값을 넣어야됨
- 시각화하려는 데이터의 개수와 각 데이터의 차원을 맞춰야 함
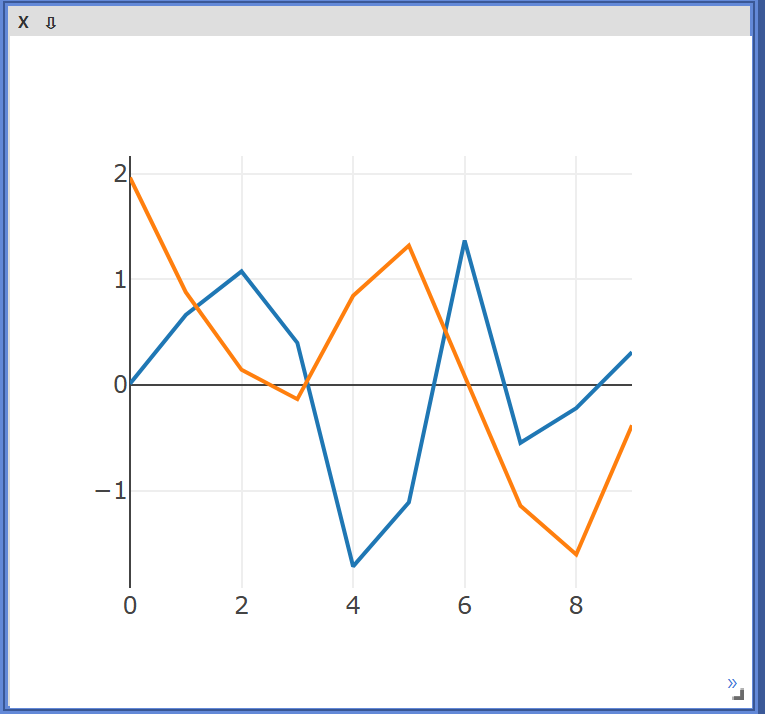
Line info
1
2
3
plt = vis.line(Y=Y_data, X=X_data, opts = dict(title='Test', showlegend=True))
plt = vis.line(Y=Y_data, X=X_data, opts = dict(title='Test', legend = ['1번'],showlegend=True))
plt = vis.line(Y=torch.randn(10,2), X = num, opts=dict(title='Test', legend=['1번','2번'],showlegend=True))
- opts에 dict 형태로 값을 추가
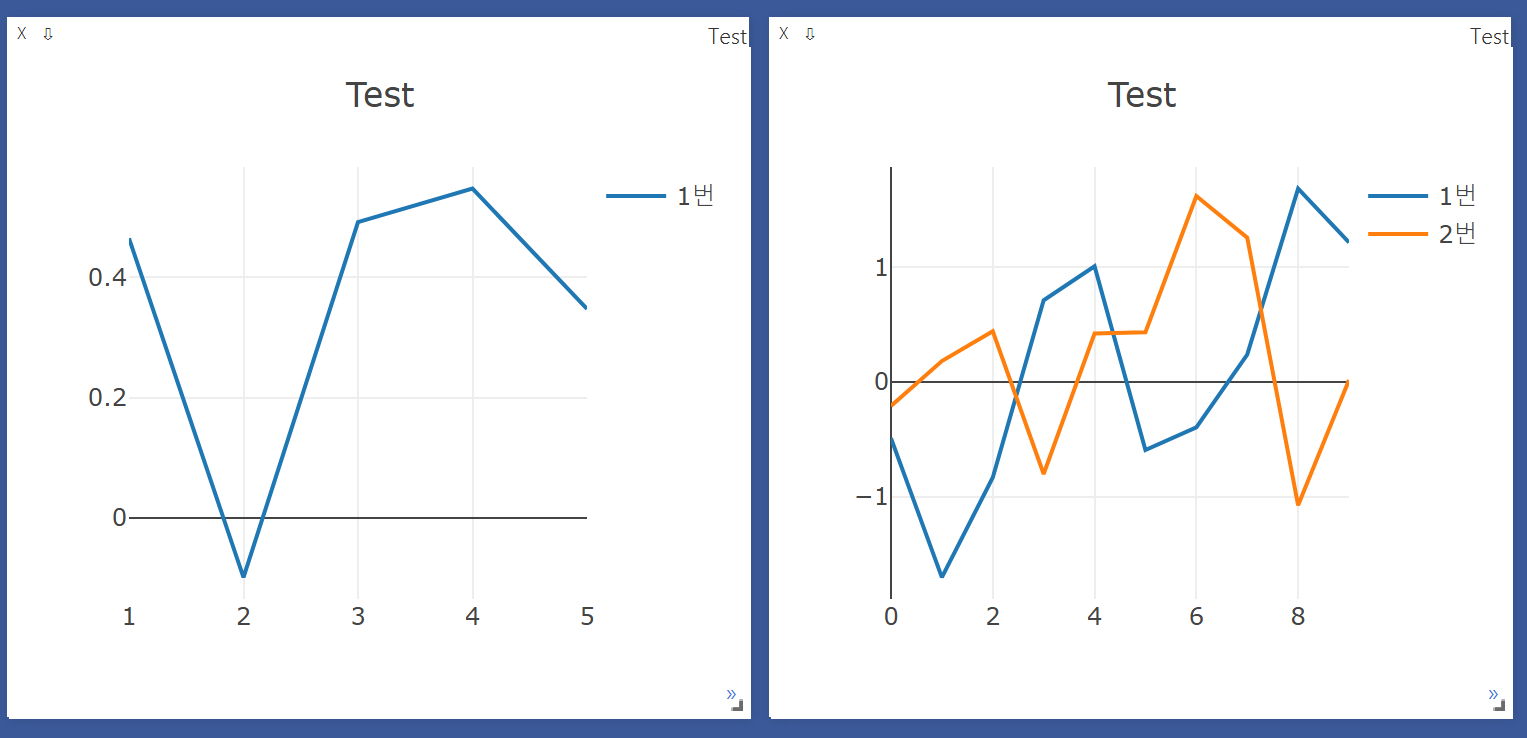
make function for update line
반복문을 통해 값을 업데이트
1
2
3
4
5
6
7
8
9
10
11
12
def loss_tracker(loss_plot, loss_value, num):
'''num, loss_value, are Tensor'''
vis.line(X=num,
Y=loss_value,
win = loss_plot,
update='append'
)
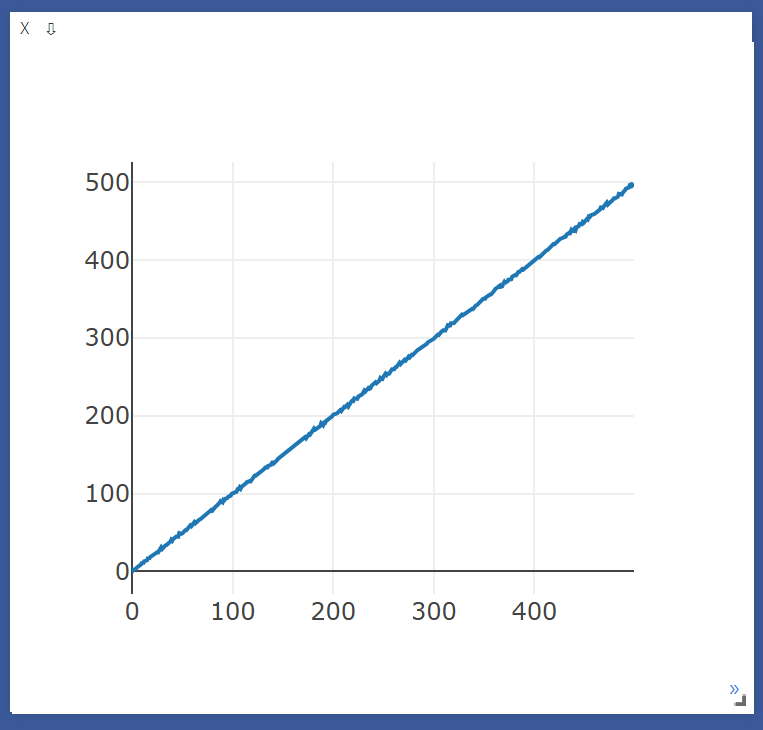
plt = vis.line(Y=torch.Tensor(1).zero_())
for i in range(500):
loss = torch.randn(1) + i
loss_tracker(plt, loss, torch.Tensor([i]))
MNIST-CNN with Visdom
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
import torch
import torch.nn as nn
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import torch.nn.init
import visdom
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1,32,kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.layer2 = nn.Sequential(
nn.Conv2d(32,64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.layer3 = nn.Sequential(
nn.Conv2d(64,128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.fc1 = nn.Linear(3*3*128, 625)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(625, 10, bias =True)
torch.nn.init.xavier_uniform_(self.fc1.weight)
torch.nn.init.xavier_uniform_(self.fc2.weight)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
out = out.view(out.size(0), -1)
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
return out
vis = visdom.Visdom()
vis.close(env="main")
# plot 생성
def loss_tracker(loss_plot, loss_value, num):
'''num, loss_value, are Tensor'''
vis.line(X=num,
Y=loss_value,
win = loss_plot,
update='append'
)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
torch.manual_seed(777)
if device =='cuda':
torch.cuda.manual_seed_all(777)
#parameters
learning_rate = 0.001
training_epochs = 15
batch_size = 32
#MNIST dataset
mnist_train = dsets.MNIST(root='MNIST_data/',
train = True,
transform=transforms.ToTensor(),
download=True)
mnist_test = dsets.MNIST(root='MNIST_data/',
train=False,
transform = transforms.ToTensor(),
download=True)
data_loader = torch.utils.data.DataLoader(dataset=mnist_train,
batch_size = batch_size,
shuffle =True,
drop_last=True)
model = CNN().to(device)
value = (torch.Tensor(1,1,28,28)).to(device)
print( (model(value)).shape )
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr = learning_rate)
loss_plt = vis.line(Y=torch.Tensor(1).zero_(),opts=dict(title='loss_tracker', legend=['loss'], showlegend=True))
#training
total_batch = len(data_loader)
for epoch in range(training_epochs):
avg_cost = 0
for X, Y in data_loader:
X = X.to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = model(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
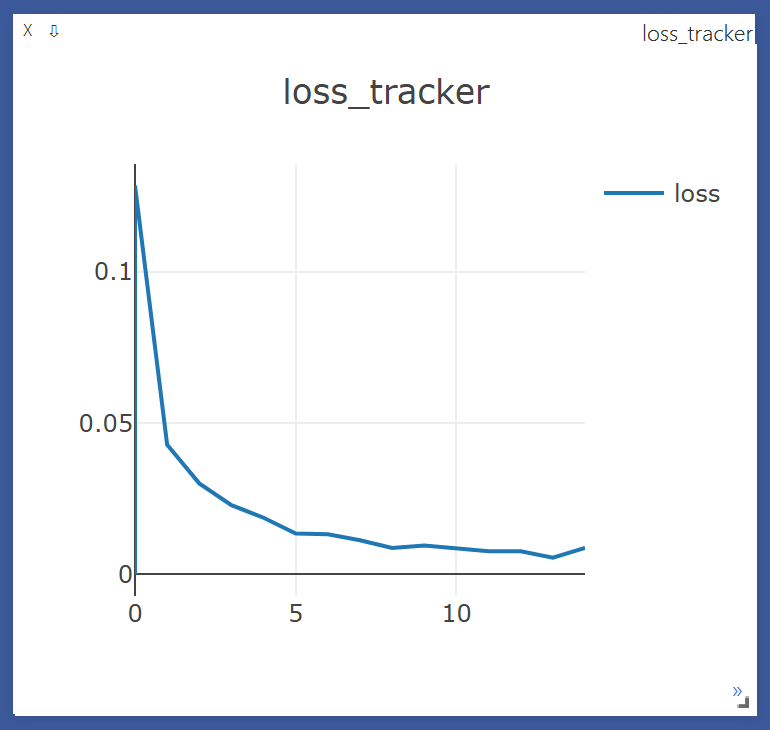
print('[Epoch:{}] cost = {}'.format(epoch+1, avg_cost))
# 1Epoch 마다 avg_cost 추가
loss_tracker(loss_plt, torch.Tensor([avg_cost]), torch.Tensor([epoch]))
print('Learning Finished!')
with torch.no_grad():
X_test = mnist_test.test_data.view(len(mnist_test), 1, 28, 28).float().to(device)
Y_test = mnist_test.test_labels.to(device)
prediction = model(X_test)
correct_prediction = torch.argmax(prediction, 1) == Y_test
accuracy = correct_prediction.float().mean()
print('Accuracy:', accuracy.item())
학습 시작
학습 종료
This post is licensed under CC BY 4.0 by the author.