[모두를 위한 딥러닝 시즌2] Lab-11-1 RNN basics
[모두를 위한 딥러닝 시즌2] Lab-11-1 RNN basics
RNN in Pytorch
- 데이터 입력과 텐서 변환
- PyTorch에서 입력 데이터는 3차원 텐서 형태
- Batch Size, Sequence Length, Feature Dimension를 의미한다
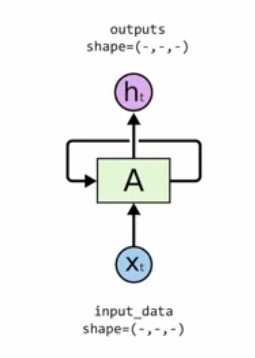
- RNN 네트워크에 데이터 전달
- 입력 데이터 $x_t$를 RNN에 전달하면, 결과값 $h_t$와 hidden state를 반환
1
2
rnn = torch.nn.RNN(input_size, hidden_size)
outputs, _status = rnn(input_data)
Simple Example
Input
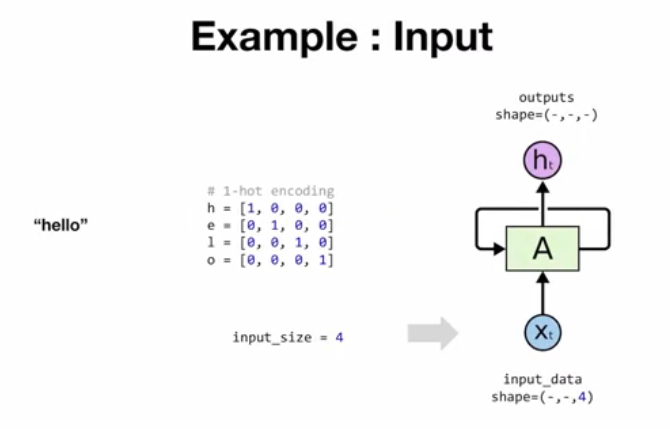
- One-Hot Encoding
- 단어 “hello”는 각 문자별로 벡터화되어, 인덱스 위치에만 1을 가지는 형태로 변환
- 입력 크기
- 문자의 개수에 따라 입력 차원이 결정
워드 임베딩(Word Embedding)
원-핫 인코딩 대신 사용 가능
단어를 고차원 공간에서 밀집된 벡터(dense vector)로 변환하는 기법으로, 단어 간의 의미적 유사성을 학습
원-핫 인코딩과 달리 벡터 차원이 낮고, 단어 간 관계를 반영하여 효율적인 계산과 더 나은 학습이 가능 대표 모델 : Word2Vec, GloVe
Hidden State
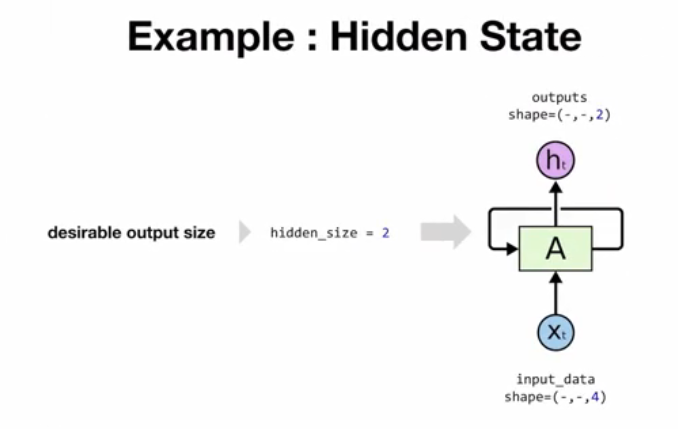
- 시퀀스 인풋을 처리하고 결과를 되돌려 다음 시퀀스 인풋과 연결하는 구조
- Hidden State 사이즈는 출력 데이터 사이즈와 같다 → 원하는 벡터 사이즈에 따라 히든 사이즈를 조정해야 한다
- 예시) 감정 분석에서 슬픔, 기쁨, 화남 등 세 가지 감정을 다룰 경우, 히든 사이즈는 3이 된다
Hidden Size와 Output Size 비교
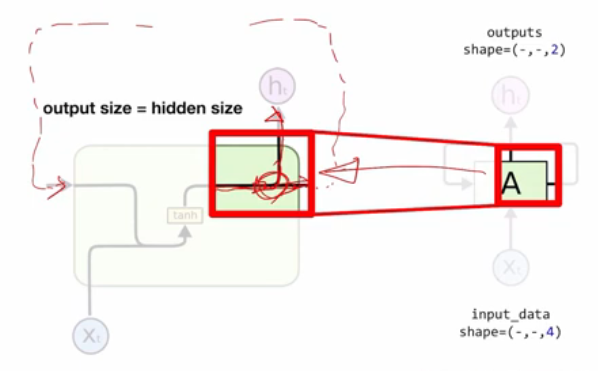
- Output, Hidden State로 출력 직전의 똑같은 값이 전달된다
- hidden state는 그대로 다음 input으로 입력되어 hidden state의 사이즈는 output 사이즈와 동일하다.
Sequence Length
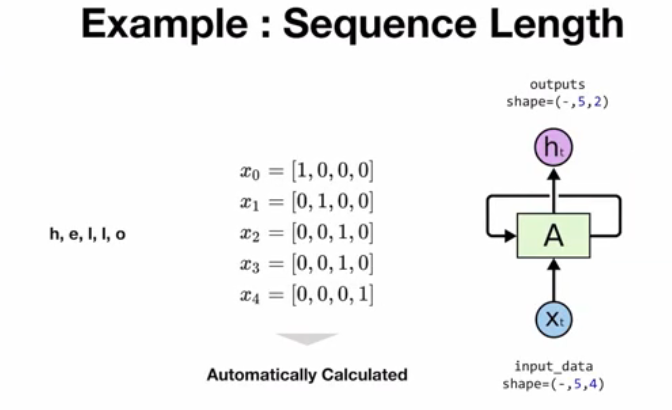
- Sequence Data $x_{(0)}$부터 $x_{(t)}$까지 입력할 때 t+1 개의 Sequence Length를 갖는다
- 예시) “hello”일 경우, Sequence Length는 문자의 개수 = 5
- PyTorch에서는 입력 시퀀스의 길이를 모델이 자동으로 파악한다
Batch Size
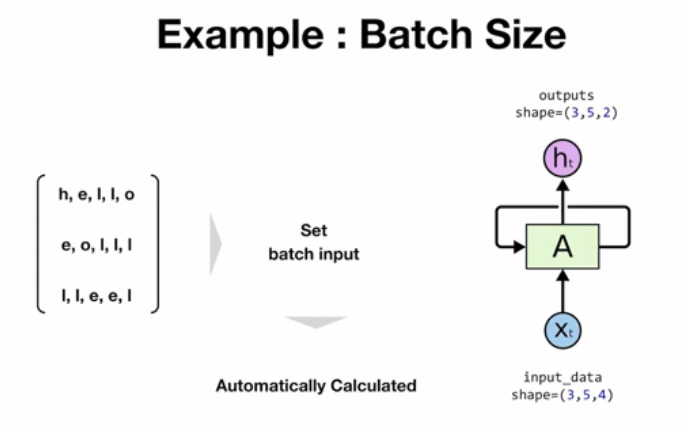
- 여러 개의 데이터를 하나의 batch로 묶어 학습
- 예시) one-hot encoding에서 선언한 h,e,l,o 를 조합하여 만든 단어 중 3개의 단어(hello, eolll, lleel)를 batch로 묶어 학습
- PyTorch에서는 batch size의 길이를 모델이 자동으로 파악한다
Code
- input size, hidden size 정의
- batch를 통해 input data 생성
- RNN에 input data 입력
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
import torch
import numpy as np
# 결과를 재현 가능하게 만들기 위해 랜덤 시드 설정
torch.manual_seed(0)
# 입력 데이터의 크기와 히든 상태의 크기 정의
input_size = 4 # 입력 데이터의 차원
hidden_size = 2 # 히든 스테이트의 차원
# RNN에 입력될 데이터를 생성하는 부분
# 'hello'와 같은 단어를 원-핫 인코딩 방식으로 표현
h = [1, 0, 0, 0] # 'h'를 원-핫 인코딩
e = [0, 1, 0, 0] # 'e'를 원-핫 인코딩
l = [0, 0, 1, 0] # 'l'을 원-핫 인코딩
o = [0, 0, 0, 1] # 'o'를 원-핫 인코딩
# 세 개의 시퀀스 데이터 생성
# 각 시퀀스는 (5, 4) 크기를 가지며, 총 3개의 시퀀스를 포함
input_data_np = np.array([
[h, e, l, l, o], # 첫 번째 시퀀스 ('hello')
[e, o, l, l, l], # 두 번째 시퀀스
[l, l, e, e, l] # 세 번째 시퀀스
], dtype=np.float32)
# numpy 배열을 PyTorch 텐서로 변환
input_data = torch.Tensor(input_data_np)
# RNN 모델 선언
# 입력 크기(input_size)와 히든 크기(hidden_size)를 설정
rnn = torch.nn.RNN(input_size, hidden_size)
# RNN에 입력 데이터를 전달하여 출력 계산
outputs, _status = rnn(input_data)
print(outputs)
# tensor([[[-0.7497, -0.6135],
# [-0.5282, -0.2473],
# [-0.9136, -0.4269],
# [-0.9136, -0.4269],
# [-0.9028, 0.1180]],
# [[-0.5753, -0.0070],
# [-0.9052, 0.2597],
# [-0.9173, -0.1989],
# [-0.9173, -0.1989],
# [-0.8996, -0.2725]],
# [[-0.9077, -0.3205],
# [-0.8944, -0.2902],
# [-0.5134, -0.0288],
# [-0.5134, -0.0288],
# [-0.9127, -0.2222]]], grad_fn=<StackBackward0>)
print(outputs.size()) # (배치 크기, 시퀀스 길이, 히든 상태 크기)
# torch.Size([3, 5, 2])
This post is licensed under CC BY 4.0 by the author.