[모두를 위한 딥러닝 시즌2] Lab-11-5 RNN seq2seq
[모두를 위한 딥러닝 시즌2] Lab-11-5 RNN seq2seq
Seq2Seq(Sequence to Sequence)
- sequence를 입력 받고 sequence를 출력하는 모델
- 예) 번역, 챗봇
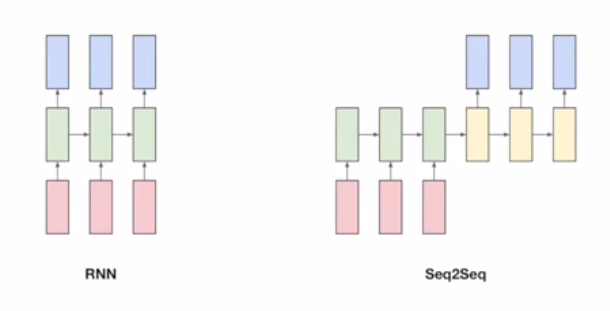
RNN과 Seq2Seq의 차이점
- RNN은 단어 입력 시마다 출력 생성
- 챗봇 상황에서 사용자가 문장을 다 듣기 전에 적절한 답변을 생성하지 못하는 경우가 발생할 수 있으며, 이는 문장의 맥락을 고려하지 않기 때문이다
- 실제로 우리 생활에서도 문장을 다 듣기도 전에 답변을 만들다 보면, 그 문장 끝에서의 어떤 변화 때문에 제대로 된 답변을 하기가 어려운 경우들이 발생한다
- 이러한 문제를 해결하기 위해, 끝까지 듣고 적절한 응답을 생성할 수 있는 Seq2Seq 모델이 고안되었다
- 입력을 끝까지 처리한 후 출력을 생성하여 문맥 정보를 더 잘 활용
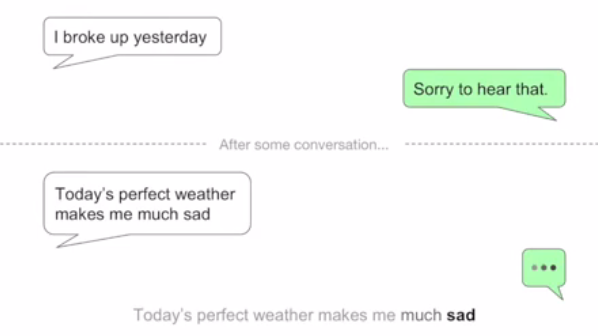
예시) 연인과 헤어진 대화 주제
처음에는 위로의 메세지를 보내지만
일정 대화를 주고받은 후, “오늘 날씨가 좋아서 더 슬퍼” 라는 메세지가 오면
RNN 모델은 “날씨가 좋아서”라는 내용으로 인해 위로와는 거리가 먼 대답을 메세지를 줄 확률이 크다
Apply Seq2Seq
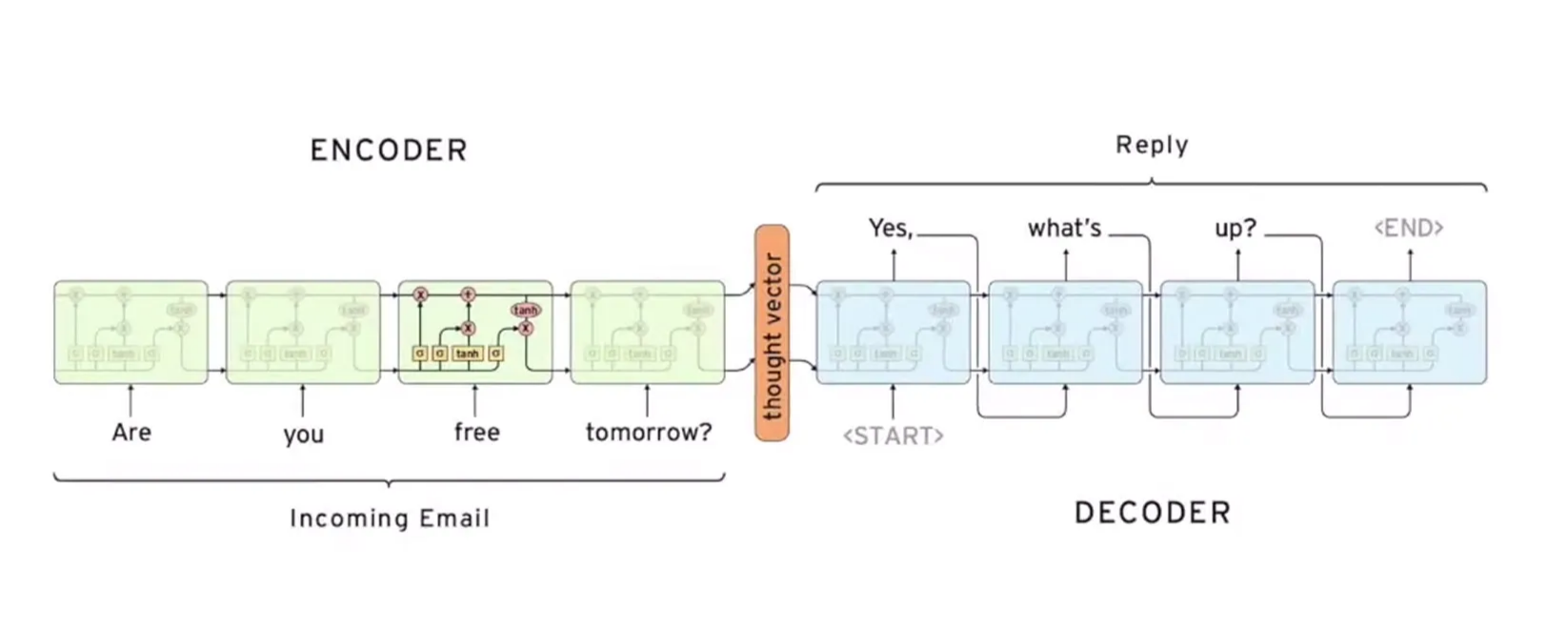
Encoder - Decoder
- Seq2Seq 모델의 핵심 기능
- Encoder
- input seq를 압축하여 vector 형태로 변환
- 압축된 vector를 Decoder로 전달 (첫 cell의 hidden state)
- Decoder
- 첫 cell에서 문장이 시작하는 start flag와 함께 작동
- Decoder의 첫 번째 output은 예측된 문장의 첫 번째 단어가 된다
- 이후 output는 이전 output과 hidden state를 기반으로 계속 예측되어 최종 문장을 형성
Code
- seq2seq모델을 사용하여 번역 task를 수행
- input으로 영어 문장이 주어지고, 이에 대응하는 한국어 문장을 output하도록 학습하고 평가하는 구조
- 데이터 전처리 과정에서는 소스 텍스트와 타겟 텍스트를 나누고, 각 문장의 최대 길이를 설정하여 학습할 데이터를 준비
- encoder와 decoder는 각각의 hidden state를 정의하고 두 클래스를 통해 이루어지는 간단한 구조
- decoder 부분에서는 encoder의 output을 기반으로 단어를 생성하기 위한 Linear Layer와 Softmax를 사용하여 최종 단어 선택
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import random
import torch
import torch.nn as nn
from torch import optim
# 문장 최대 길이 정의
SOURCE_MAX_LENGTH = 10
TARGET_MAX_LENGTH = 12
# 데이터 전처리
load_pairs, load_source_vocab, load_target_vocab = preprocess(raw, SOURCE_MAX_LENGTH, TARGET_MAX_LENGTH)
print(random.choice(load_pairs))
# 인코더와 디코더 선언
enc_hidden_size = 16
dec_hidden_size = enc_hidden_size
enc = Encoder(load_source_vocab.n_vocab, enc_hidden_size).to(device)
dec = Decoder(dec_hidden_size, load_target_vocab.n_vocab).to(device)
# 학습 실행
train(load_pairs, load_source_vocab, load_target_vocab, enc, dec, 5000, print_every=1000)
# 평가 실행
evaluate(load_pairs, load_source_vocab, load_target_vocab, enc, dec, TARGET_MAX_LENGTH)
Data Preprocessing
- 간단한 학습용 데이터로, 영어와 그에 대응하는 한국어 번역 문장이 포함된
raw리스트를 사용- 각 문장은 tab을 기준으로 영어(소스 텍스트)와 한국어(타겟 텍스트)로 구분
- 토큰 정의
- EOS_token (Start Of Sentence) : 문장이 끝났음을 나타내는 토큰 (값 = 1)
- SOS_token (End Of Sentene) : 문장이 시작됨을 나타내는 토큰 (값 = 0)
- 디코더가 학습 중 첫 번째 입력으로
SOS_token을 받고, 문장이 끝날 때는EOS_token을 출력으로 받게 됨 - 모델이 학습 중 문장의 시작과 끝을 명확히 알 수 있고, 문장이 끝나는 시점을 스스로 알 수 있도록 설정
- 문장 길이 제한
- 너무 긴 문장은 학습 효율을 떨어뜨릴 수 있으므로 제거하거나, 끝에
EOS_token을 추가하여 문장이 끝났음을 표시 - 학습 데이터에 포함된 문장의 단어 수가 특정 기준보다 크면 제외
- 너무 긴 문장은 학습 효율을 떨어뜨릴 수 있으므로 제거하거나, 끝에
- 어휘 정보 관리 (
Vocab클래스)- 각 단어를 고유 index로 매핑하고, 역으로 index를 단어로 매핑하는 딕셔너리 생성
- 새로운 단어가 추가되면 자동으로 어휘에 추가
- 데이터 전처리 함수 (
preprocess)- 소스 텍스트(영어)와 타겟 텍스트(한국어)를 나눔
- 문장의 최대 길이를 기준으로 데이터 필터링
- 단어 수를 계산하고 각 단어를 어휘에 추가
- 결과 : 학습에 사용될 문장 쌍과, 각 언어에 대한 어휘 정보 준비
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
# 랜덤 시드 설정
torch.manual_seed(0)
# GPU 사용 여부 확인
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 학습 데이터 (영어-한국어 문장 쌍)
raw = ["I feel hungry. 나는 배가 고프다.",
"Pytorch is very easy. 파이토치는 매우 쉽다.",
"Pytorch is a framework for deep learning. 파이토치는 딥러닝을 위한 프레임워크이다.",
"Pytorch is very clear to use. 파이토치는 사용하기 매우 직관적이다."]
# 문장 시작(SOS)과 끝(EOS)을 나타내는 토큰
SOS_token = 0
EOS_token = 1
# 어휘 정보 관리를 위한 클래스 정의
class Vocab:
def __init__(self):
self.vocab2index = {"<SOS>": SOS_token, "<EOS>": EOS_token} # 단어 → index
self.index2vocab = {SOS_token: "<SOS>", EOS_token: "<EOS>"} # index → 단어
self.vocab_count = {} # 단어 빈도수
self.n_vocab = len(self.vocab2index) # 어휘 크기
# 새로운 단어를 어휘집에 추가
def add_vocab(self, sentence):
for word in sentence.split(" "): # 문장을 단어로 분리
if word not in self.vocab2index:
self.vocab2index[word] = self.n_vocab
self.index2vocab[self.n_vocab] = word
self.vocab_count[word] = 1
self.n_vocab += 1
else:
self.vocab_count[word] += 1
# 긴 문장을 필터링하는 함수
def filter_pair(pair, source_max_length, target_max_length):
return len(pair[0].split(" ")) < source_max_length and len(pair[1].split(" ")) < target_max_length
# 데이터 전처리 함수
def preprocess(corpus, source_max_length, target_max_length):
print("Reading corpus...")
pairs = []
for line in corpus:
pairs.append([s for s in line.strip().lower().split("\t")]) # 소스와 타겟 문장 분리
print("Read {} sentence pairs".format(len(pairs)))
# 문장 길이 제한
pairs = [pair for pair in pairs if filter_pair(pair, source_max_length, target_max_length)]
print("Trimmed to {} sentence pairs".format(len(pairs)))
# 어휘집 생성
source_vocab = Vocab()
target_vocab = Vocab()
print("Counting words...")
for pair in pairs:
source_vocab.add_vocab(pair[0]) # 소스 어휘 추가
target_vocab.add_vocab(pair[1]) # 타겟 어휘 추가
print("Source vocab size =", source_vocab.n_vocab)
print("Target vocab size =", target_vocab.n_vocab)
return pairs, source_vocab, target_vocab
Neural Net Setting
간단한 모델로 성능 향상을 위해 추가적인 기법이 필요함
- 어텐션(Attention): 입력 시퀀스의 모든 정보를 활용하여 디코딩 성능 향상
- 하이웨이 네트워크(Highway Networks): 더 깊고 복잡한 네트워크 구성
Encoder
- 입력 텍스트(소스)를 처리하여 고정된 차원의 vector로 변환
- 입력 시퀀스를 모두 처리한 후, 마지막 hidden state를 디코더에 전달
nn.Embedding- 고차원 one-hot encoding data를 저차원의 dense vector로 변환
GRU- input data를 처리하여 hidden state를 생성
- 출력
x: GRU 출력 (각 시점의 hidden state)hidden: 최종 hidden state (다음 cell에 전달)
Decoder
- 인코더의 마지막 hidden state를 받아 디코딩 시작
- 타겟 텍스트(번역문)의 첫 단어(
SOS)를 입력으로 받아 다음 단어를 예측 - 반복적으로 다음 단어를 예측하며 타겟 텍스트를 생성
out- GRU 출력(hidden state)을 단어 index 공간으로 변환
hidden_size로 16이 들어간다면, 출력hidden_size도 16이 되는데, 이를 타겟 텍스트에 사용되고 있는 단어로 복원
softmax- 출력 분포를 확률 형태로 변환
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 간단한 인코더 정의
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size) # 단어 임베딩
self.gru = nn.GRU(hidden_size, hidden_size) # GRU 레이어
def forward(self, x, hidden):
x = self.embedding(x).view(1, 1, -1) # 임베딩
x, hidden = self.gru(x, hidden) # GRU 통과
return x, hidden
# 간단한 디코더 정의
class Decoder(nn.Module):
def __init__(self, hidden_size, output_size):
super(Decoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size, hidden_size) # 단어 임베딩
self.gru = nn.GRU(hidden_size, hidden_size) # GRU 레이어
self.out = nn.Linear(hidden_size, output_size) # 출력 레이어
self.softmax = nn.LogSoftmax(dim=1) # 소프트맥스 함수
def forward(self, x, hidden):
x = self.embedding(x).view(1, 1, -1) # 임베딩
x, hidden = self.gru(x, hidden) # GRU 통과
x = self.softmax(self.out(x[0])) # 출력 생성
return x, hidden
Encoder와 Decoder 차이점
| 항목 | Encoder | Decoder |
|---|---|---|
| 입력 데이터 | 소스 텍스트 index | 타겟 텍스트 index (또는 이전 출력 단어) |
| 출력 데이터 | 최종 히든 상태 | 다음 단어의 확률 분포 |
| 핵심 레이어 | GRU 레이어 | GRU + Linear + Softmax |
| 역할 | 입력 시퀀스를 벡터로 압축 | 벡터를 기반으로 타겟 텍스트 생성 |
nn.Embedding
단어를 dense vector로 매핑하는 워드 임베딩(Word Embedding)을 수행하는 PyTorch 레이어
one-hot vector의 희소 표현(Sparse Representation)대신 밀집 표현(Dense Representation)을 이용하여 표현
- 파라미터
input_size: 입력 토큰의 개수(사전 크기, vocabulary size)hidden_size: 출력 임베딩 벡터의 크기(차원)- 크기:
[input_size x hidden_size](예: 1000개의 단어 → 256차원 벡터)- 작동 방식
- input_size=1000이고 hidden_size=256이면, 0부터 999까지의 단어 ID를 256차원 벡터로 변환
- 예시 : ‘딥러닝’ = [0.1 1.1 0.5 2.1 1.1 2.2 …]
- 장점
- 원핫 인코딩 대비 메모리 절약
- 학습을 통해 단어 간의 의미적 관계를 파악할 수 있음
Training
- Tensorize
- one-hot vector를 tensor 형태로 변환
- Teacher Forcing
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
# 문장을 인덱스 텐서로 변환
def tensorize(vocab, sentence):
indexes = [vocab.vocab2index[word] for word in sentence.split(" ")]
indexes.append(vocab.vocab2index["<EOS>"]) # EOS 추가
return torch.Tensor(indexes).long().to(device).view(-1, 1)
# 학습 함수
def train(pairs, source_vocab, target_vocab, encoder, decoder, n_iter, print_every=1000, learning_rate=0.01):
loss_total = 0
encoder_optimizer = optim.SGD(encoder.parameters(), lr=learning_rate)
decoder_optimizer = optim.SGD(decoder.parameters(), lr=learning_rate)
training_batch = [random.choice(pairs) for _ in range(n_iter)]
training_source = [tensorize(source_vocab, pair[0]) for pair in training_batch]
training_target = [tensorize(target_vocab, pair[1]) for pair in training_batch]
criterion = nn.NLLLoss() # 손실 함수
for i in range(1, n_iter + 1):
source_tensor = training_source[i - 1]
target_tensor = training_target[i - 1]
encoder_hidden = torch.zeros([1, 1, encoder.hidden_size]).to(device) # 초기 히든 상태
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
source_length = source_tensor.size(0)
target_length = target_tensor.size(0)
loss = 0
# 인코더 학습
for enc_input in range(source_length):
_, encoder_hidden = encoder(source_tensor[enc_input], encoder_hidden)
decoder_input = torch.Tensor([[SOS_token]]).long().to(device)
decoder_hidden = encoder_hidden # 인코더 출력 → 디코더 입력
# 디코더 학습
for di in range(target_length):
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
loss += criterion(decoder_output, target_tensor[di]) # 손실 계산
decoder_input = target_tensor[di] # Teacher Forcing
loss.backward() # 역전파
encoder_optimizer.step()
decoder_optimizer.step()
loss_iter = loss.item() / target_length
loss_total += loss_iter
if i % print_every == 0:
loss_avg = loss_total / print_every
loss_total = 0
print("[{} - {}%] loss = {:05.4f}".format(i, i / n_iter * 100, loss_avg))
Teacher Forcing
디코더의 다음 input으로 예측값 대신 실제 정답을 사용하는 학습 기법
decoder의gru의 예측값을 다음 셀에 넣어주는 것이 아닌 직접 정답을 넣어주는 방식
빠른 학습이 가능하지만, 학습이 불안정해질 가능성이 있다
일반적으로 Teacher Forcing 비율을 조정하여 학습 안정성과 성능 간의 균형을 맞춰서 사용
Evaluation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 모델 평가 함수
def evaluate(pairs, source_vocab, target_vocab, encoder, decoder, target_max_length):
for pair in pairs:
print(">", pair[0]) # 입력 문장
print("=", pair[1]) # 실제 정답
source_tensor = tensorize(source_vocab, pair[0])
source_length = source_tensor.size()[0]
encoder_hidden = torch.zeros([1, 1, encoder.hidden_size]).to(device)
for ei in range(source_length):
_, encoder_hidden = encoder(source_tensor[ei], encoder_hidden)
decoder_input = torch.Tensor([[SOS_token]]).long().to(device)
decoder_hidden = encoder_hidden
decoded_words = []
for di in range(target_max_length):
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
_, top_index = decoder_output.data.topk(1) # 가장 높은 확률의 단어 선택
if top_index.item() == EOS_token: # EOS 검사
decoded_words.append("<EOS>")
break
else:
decoded_words.append(target_vocab.index2vocab[top_index.item()])
decoder_input = top_index.squeeze().detach()
predict_words = decoded_words
predict_sentence = " ".join(predict_words)
print("<", predict_sentence) # 예측된 문장
print("")
This post is licensed under CC BY 4.0 by the author.