[모두를 위한 딥러닝 시즌2] Lab-11-6 RNN PackedSequence
[모두를 위한 딥러닝 시즌2] Lab-11-6 RNN PackedSequence
Examples of sequential data
sequential data는 순서와 흐름이 중요한 형태
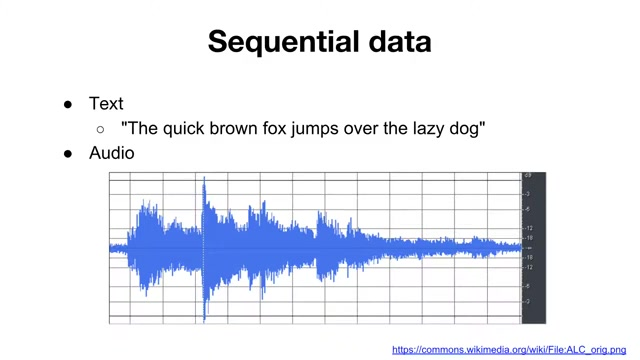
- 텍스트(Text): 문장은 단어의 개수가 서로 다름
- 예: “The quick brown fox jumps over the lazy dog” → 단어 개수: 9
- 오디오(Audio): 오디오 데이터는 시간과 샘플링 비율에 따라 길이가 달라짐
이와 같은 데이터는 길이가 일정하지 않아서 배치(batch) 처리에 어려움
How do we make a batch with multiple sequence sizes?
Padding Method
- 가장 긴 시퀀스의 길이에 맞추어 짧은 시퀀스에 패딩 토큰(
<pad>)을 추가 - 장점
- 데이터가 일정한 크기로 맞춰지므로 처리하기 쉬움
- 단점
- 계산할 필요가 없는 패딩 토큰까지 연산에 포함되어 비효율적

- 주어진 데이터
- “hello world” → 길이: 11
- “path” → 길이: 4
- “short circuit” → 길이: 13
- 가장 긴 sequence인 short circuit에 맞추어 나머지 데이터에 Padding 적용
Packing Method
- 패딩 없이 시퀀스의 유효한 데이터 길이만 저장하는 방식
- 장점
- padding method에 비해 효율적
- 단점
- padding method에 비해 구현이 복잡함
- Pytorch에서는 데이터가 길이 내림차순으로 정렬되어야 함
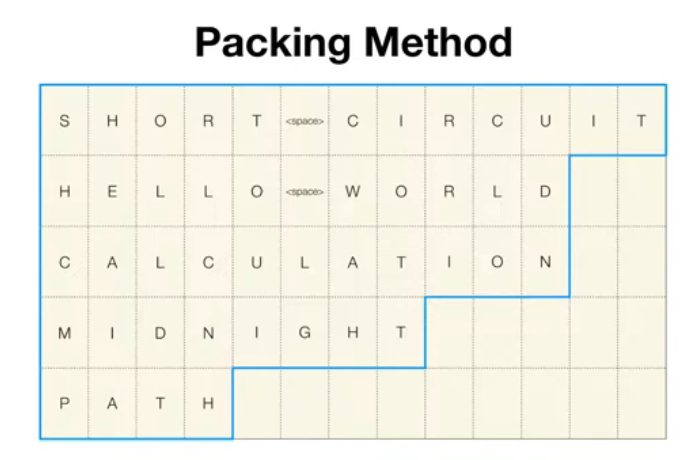
PyTorch에서 내림차순 정렬이 필요한 이유
PyTorch의 RNN 계열 모듈(RNN,LSTM,GRU)이 PackedSequence 객체를 효율적으로 처리하도록 설계되었기 때문이다
TensorFlow, Keras, JAX 등 다른 프레임워크나 라이브러리에서는 다른 방식(마스킹 등)으로 처리PyTorch의
PackedSequence객체는 다음과 같은 구조
1. Data: 길이가 다른 시퀀스에서 유효한 데이터를 순차적으로 모아 하나의 텐서로 만듦
2. Batch Sizes: 각 시간 단계에서 처리해야 할 배치 크기를 기록
이 구조를 효율적으로 관리하기 위해 PyTorch는 내부적으로 배치 데이터가 내림차순으로 정렬된다고 가정
PyTorch Library Funchions
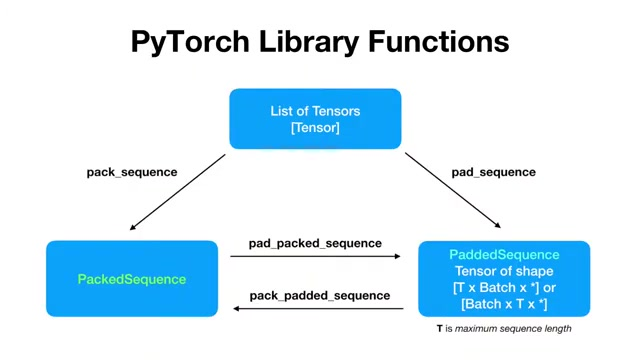
Data 처리
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
import torch
import numpy as np
from torch.nn.utils.rnn import pad_sequence, pack_sequence, pack_padded_sequence, pad_packed_sequence
# 랜덤한 단어 리스트 (입력 데이터)
data = ['hello world',
'midnight',
'calculation',
'path',
'short circuit']
# 1. 문자 집합 생성 및 딕셔너리 구성
char_set = ['<pad>'] + list(set(char for seq in data for char in seq)) # 모든 문자를 가져오고 <pad> 토큰 추가
char2idx = {char: idx for idx, char in enumerate(char_set)} # 문자 → 인덱스 매핑 딕셔너리 생성
print('char_set:', char_set) # 문자 집합 확인
print('char_set length:', len(char_set)) # 문자 집합 크기 확인
# char_set: ['<pad>', 'i', 'p', 'd', 'n', ' ', 'h', 's', 'c', 'm', 't', 'l', 'e', 'w', 'g', 'a', 'u', 'r', 'o']
# char_set length: 19
# 2. 문자 → 인덱스로 변환 후 텐서 리스트 생성
X = [torch.LongTensor([char2idx[char] for char in seq]) for seq in data]
# 변환된 결과 확인
for sequence in X:
print(sequence)
# tensor([ 6, 12, 11, 11, 18, 5, 13, 18, 17, 11, 3])
# tensor([ 9, 1, 3, 4, 1, 14, 6, 10])
# tensor([ 8, 15, 11, 8, 16, 11, 15, 10, 1, 18, 4])
# tensor([ 2, 15, 10, 6])
# tensor([ 7, 6, 18, 17, 10, 5, 8, 1, 17, 8, 16, 1, 10])
# 3. 시퀀스 길이 리스트 생성 (pack_padded_sequence에서 사용)
lengths = [len(seq) for seq in X]
print('lengths:', lengths)
# lengths: [11, 8, 11, 4, 13]
pad_sequence
List of Tensors를 받아pad_sequence를 생성- 추가 옵션
batch_first: 배치 차원을 맨 앞으로 지정 (True설정 시(batch_size, max_sequence_length)형태)padding_value: 패딩에 사용할 값을 지정 (기본값:0)
1
2
3
4
5
6
7
8
9
10
# 4. 패딩된 텐서 생성 (Batch x Max_Sequence_Length 형태)
padded_sequence = pad_sequence(X, batch_first=True) # X를 패딩된 시퀀스로 변환
print(padded_sequence)
print(padded_sequence.shape) # 패딩된 텐서의 크기 확인
# tensor([[ 6, 12, 11, 11, 18, 5, 13, 18, 17, 11, 3, 0, 0],
# [ 9, 1, 3, 4, 1, 14, 6, 10, 0, 0, 0, 0, 0],
# [ 8, 15, 11, 8, 16, 11, 15, 10, 1, 18, 4, 0, 0],
# [ 2, 15, 10, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# [ 7, 6, 18, 17, 10, 5, 8, 1, 17, 8, 16, 1, 10]])
# torch.Size([5, 13])
pack_sequence
List of Tensors를PackedSequence객체로 변환
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 5. 시퀀스를 길이 기준 내림차순 정렬
sorted_idx = sorted(range(len(lengths)), key=lengths.__getitem__, reverse=True) # 길이를 기준으로 정렬 인덱스 생성
sorted_X = [X[idx] for idx in sorted_idx] # 정렬된 시퀀스 생성
# 정렬된 결과 확인
for sequence in sorted_X:
print(sequence)
# tensor([ 7, 6, 18, 17, 10, 5, 8, 1, 17, 8, 16, 1, 10])
# tensor([ 6, 12, 11, 11, 18, 5, 13, 18, 17, 11, 3])
# tensor([ 8, 15, 11, 8, 16, 11, 15, 10, 1, 18, 4])
# tensor([ 9, 1, 3, 4, 1, 14, 6, 10])
# tensor([ 2, 15, 10, 6])
# 6. PackedSequence 생성
packed_sequence = pack_sequence(sorted_X)
print(packed_sequence)
# PackedSequence(data=tensor([ 7, 6, 8, 9, 2, 6, 12, 15, 1, 15, 18, 11, 11, 3, 10, 17, 11, 8,
# 4, 6, 10, 18, 16, 1, 5, 5, 11, 14, 8, 13, 15, 6, 1, 18, 10, 10,
# 17, 17, 1, 8, 11, 18, 16, 3, 4, 1, 10]), batch_sizes=tensor([5, 5, 5, 5, 4, 4, 4, 4, 3, 3, 3, 1, 1]), sorted_indices=None, unsorted_indices=None)
pad_packed_sequence
PackedSequence객체를 다시pad_sequence로 변환
1
2
3
4
5
6
# 10. PackedSequence → PaddedSequence 변환
unpacked_sequence, seq_lengths = pad_packed_sequence(embedded_packed_seq, batch_first=True)
print(unpacked_sequence.shape) # 변환된 패딩된 텐서 크기
print(seq_lengths) # 각 시퀀스의 원래 길이
# torch.Size([5, 13, 19])
# tensor([13, 11, 11, 8, 4])
pack_padded_sequence
pad_sequence를PackedSequence로 변환
1
2
3
4
5
6
7
8
9
10
11
12
# 패딩된 텐서를 사용하여 임베딩
embedded_padded_sequence = eye[pad_sequence(sorted_X, batch_first=True)]
print(embedded_padded_sequence.shape)
# torch.Size([5, 13, 19])
# 패딩된 텐서를 PackedSequence로 변환
sorted_lengths = sorted(lengths, reverse=True)
new_packed_sequence = pack_padded_sequence(embedded_padded_sequence, sorted_lengths, batch_first=True)
print(new_packed_sequence.data.shape) # PackedSequence 데이터 크기
print(new_packed_sequence.batch_sizes) # 각 시퀀스에서 배치 크기
# torch.Size([47, 19])
# tensor([5, 5, 5, 5, 4, 4, 4, 4, 3, 3, 3, 1, 1])
전체 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
import torch
import numpy as np
from torch.nn.utils.rnn import pad_sequence, pack_sequence, pack_padded_sequence, pad_packed_sequence
# 랜덤한 단어 리스트 (입력 데이터)
data = ['hello world',
'midnight',
'calculation',
'path',
'short circuit']
# 1. 문자 집합 생성 및 딕셔너리 구성
char_set = ['<pad>'] + list(set(char for seq in data for char in seq)) # 모든 문자를 가져오고 <pad> 토큰 추가
char2idx = {char: idx for idx, char in enumerate(char_set)} # 문자 → 인덱스 매핑 딕셔너리 생성
print('char_set:', char_set) # 문자 집합 확인
print('char_set length:', len(char_set)) # 문자 집합 크기 확인
# char_set: ['<pad>', 'i', 'p', 'd', 'n', ' ', 'h', 's', 'c', 'm', 't', 'l', 'e', 'w', 'g', 'a', 'u', 'r', 'o']
# char_set length: 19
# 2. 문자 → 인덱스로 변환 후 텐서 리스트 생성
X = [torch.LongTensor([char2idx[char] for char in seq]) for seq in data]
# 변환된 결과 확인
for sequence in X:
print(sequence)
# tensor([ 6, 12, 11, 11, 18, 5, 13, 18, 17, 11, 3])
# tensor([ 9, 1, 3, 4, 1, 14, 6, 10])
# tensor([ 8, 15, 11, 8, 16, 11, 15, 10, 1, 18, 4])
# tensor([ 2, 15, 10, 6])
# tensor([ 7, 6, 18, 17, 10, 5, 8, 1, 17, 8, 16, 1, 10])
# 3. 시퀀스 길이 리스트 생성 (pack_padded_sequence에서 사용)
lengths = [len(seq) for seq in X]
print('lengths:', lengths)
# lengths: [11, 8, 11, 4, 13]
# 4. 패딩된 텐서 생성 (Batch x Max_Sequence_Length 형태)
padded_sequence = pad_sequence(X, batch_first=True) # X를 패딩된 시퀀스로 변환
print(padded_sequence)
print(padded_sequence.shape) # 패딩된 텐서의 크기 확인
# tensor([[ 6, 12, 11, 11, 18, 5, 13, 18, 17, 11, 3, 0, 0],
# [ 9, 1, 3, 4, 1, 14, 6, 10, 0, 0, 0, 0, 0],
# [ 8, 15, 11, 8, 16, 11, 15, 10, 1, 18, 4, 0, 0],
# [ 2, 15, 10, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# [ 7, 6, 18, 17, 10, 5, 8, 1, 17, 8, 16, 1, 10]])
# torch.Size([5, 13])
# 5. 시퀀스를 길이 기준 내림차순 정렬
sorted_idx = sorted(range(len(lengths)), key=lengths.__getitem__, reverse=True) # 길이를 기준으로 정렬 인덱스 생성
sorted_X = [X[idx] for idx in sorted_idx] # 정렬된 시퀀스 생성
# 정렬된 결과 확인
for sequence in sorted_X:
print(sequence)
# tensor([ 7, 6, 18, 17, 10, 5, 8, 1, 17, 8, 16, 1, 10])
# tensor([ 6, 12, 11, 11, 18, 5, 13, 18, 17, 11, 3])
# tensor([ 8, 15, 11, 8, 16, 11, 15, 10, 1, 18, 4])
# tensor([ 9, 1, 3, 4, 1, 14, 6, 10])
# tensor([ 2, 15, 10, 6])
# 6. PackedSequence 생성
packed_sequence = pack_sequence(sorted_X)
print(packed_sequence)
# PackedSequence(data=tensor([ 7, 6, 8, 9, 2, 6, 12, 15, 1, 15, 18, 11, 11, 3, 10, 17, 11, 8,
# 4, 6, 10, 18, 16, 1, 5, 5, 11, 14, 8, 13, 15, 6, 1, 18, 10, 10,
# 17, 17, 1, 8, 11, 18, 16, 3, 4, 1, 10]), batch_sizes=tensor([5, 5, 5, 5, 4, 4, 4, 4, 3, 3, 3, 1, 1]), sorted_indices=None, unsorted_indices=None)
# 7. 패딩된 텐서를 사용한 원핫 임베딩
eye = torch.eye(len(char_set)) # (len(char_set), len(char_set)) 크기의 단위 행렬 생성
embedded_tensor = eye[padded_sequence] # 원핫 임베딩된 텐서
print(embedded_tensor.shape) # (Batch_size, max_sequence_length, number_of_input_tokens)
# torch.Size([5, 13, 19])
# 8. PackedSequence를 사용한 원핫 임베딩
embedded_packed_seq = pack_sequence([eye[X[idx]] for idx in sorted_idx])
print(embedded_packed_seq.data.shape)
# torch.Size([47, 19])
# 9. RNN 선언 및 실행
rnn = torch.nn.RNN(input_size=len(char_set), hidden_size=30, batch_first=True) # RNN 레이어 선언
rnn_output, hidden = rnn(embedded_tensor) # 패딩된 시퀀스 입력
print(rnn_output.shape) # RNN 출력 크기 (batch_size, max_seq_length, hidden_size)
print(hidden.shape) # 히든 상태 크기 (num_layers * num_directions, batch_size, hidden_size)
# torch.Size([5, 13, 30])
# torch.Size([1, 5, 30])
# PackedSequence를 사용한 RNN 실행
rnn_output, hidden = rnn(embedded_packed_seq)
print(rnn_output.data.shape) # RNN 출력 데이터 크기
print(hidden.data.shape) # 히든 상태 데이터 크기
# torch.Size([47, 30])
# torch.Size([1, 5, 30])
# 10. PackedSequence → PaddedSequence 변환
unpacked_sequence, seq_lengths = pad_packed_sequence(embedded_packed_seq, batch_first=True)
print(unpacked_sequence.shape) # 변환된 패딩된 텐서 크기
print(seq_lengths) # 각 시퀀스의 원래 길이
# torch.Size([5, 13, 19])
# tensor([13, 11, 11, 8, 4])
# 패딩된 텐서를 사용하여 임베딩
embedded_padded_sequence = eye[pad_sequence(sorted_X, batch_first=True)]
print(embedded_padded_sequence.shape)
# torch.Size([5, 13, 19])
# 패딩된 텐서를 PackedSequence로 변환
sorted_lengths = sorted(lengths, reverse=True)
new_packed_sequence = pack_padded_sequence(embedded_padded_sequence, sorted_lengths, batch_first=True)
print(new_packed_sequence.data.shape) # PackedSequence 데이터 크기
print(new_packed_sequence.batch_sizes) # 각 시퀀스에서 배치 크기
# torch.Size([47, 19])
# tensor([5, 5, 5, 5, 4, 4, 4, 4, 3, 3, 3, 1, 1])
This post is licensed under CC BY 4.0 by the author.